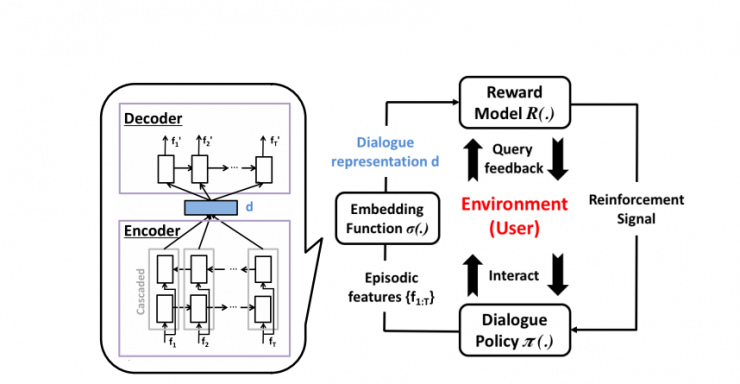
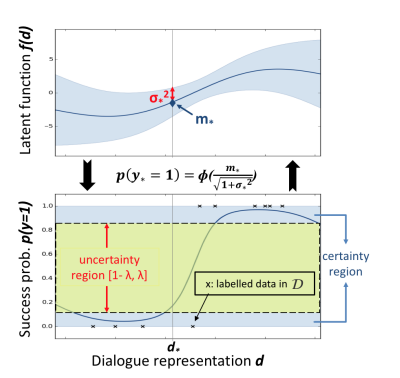
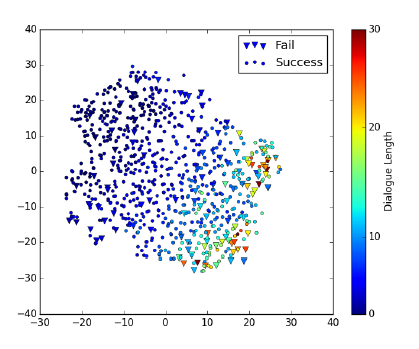
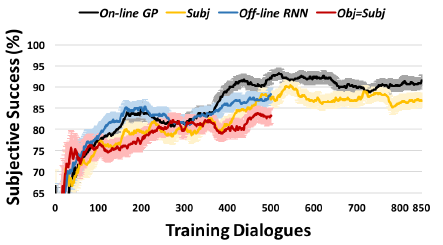
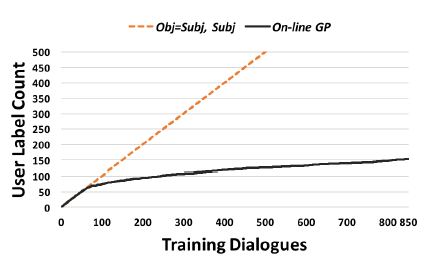
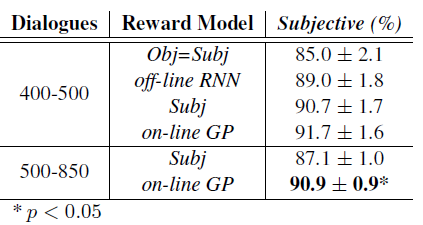
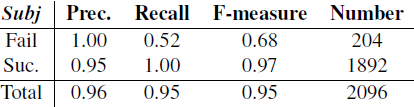
Joint compilation: Chen Zhen, Zhang Min, Gao Fei The ability to calculate the correct reward function is critical to optimizing the dialogue system through learning. In real world applications, using explicit user feedback as a reward signal is often unreliable, and the cost of collecting feedback is also very high. However, this problem can be mitigated if the user's intentions or data can be known in advance to be able to pre-train the mission success predictor offline. In practice, both of these are less suitable for most applications in reality. Here we propose an online learning framework. Through active learning with a Gaussian process model, dialogue strategies can be trained together in a reward mode. The Gaussian process has developed a series of continuous spatial dialogue representations, but all have been done using unconditional recursive neural network coding and decoding. The experimental results show that the proposed framework can greatly reduce the cost of data annotation and reduce the feedback of noisy users in dialogue strategy learning. The Speaking Dialogue System (SDS) allows the use of natural language for human-computer interaction. They can be broadly divided into two types: a chat-based system whose main goal is to talk to users and provide reasonable, context-sensitive answers; a mission-oriented system is the main task to help users Achieve specific goals (for example, discovering hotels, movies, or transit schedules). The latter is usually based on the design of the ontology structure (or database) to determine the areas that the system can talk about. It is an important task how the church system correctly answers in task-based SDS. This kind of dialogue management is often a manual process of specifying the dialogue, which directly determines the quality of the dialogue. Recently, dialogue management has been able to automatically optimize and solve RL problems. In this framework, the system learns the potential for delaying learning goals caused by trial or error processes, but this is generally determined by the reward function. Figure 1: An example of a mission-oriented dialogue and its pre-defined tasks and outcome evaluation. In a task-oriented dialogue system, a typical method is to determine that the reward mechanism is to use a small round of punishment mechanism to encourage shortening the dialogue and give positive rewards after each successful interaction. Figure 1 is an example of a task-type conversation. It is a dialog system that is set up specifically for paying users. When the user initiates the completion of a specific task, whether the dialogue is successful is determined by the user's subjective response or based on objective criteria for the completion of a particular task. However, in reality, the user's goal is generally not known in advance, which also makes the feedback evaluation method not show up. Moreover, the rating of the target is inflexible, and it can be seen from Figure 1 that if the user does not strictly follow the task flow, the probability of failure is very large. This result is caused by the mismatch between the target and the subject. However, relying solely on subjective sorting is also problematic because the subjects of crowd sources often give inaccurate responses, and humans are not willing to expand interactions to give feedback, leading to learning instability. In order to filter out erroneous user feedback, Gasic et al. use just the same dialogue between subject and object. However, in most real-life tasks, this is inefficient and infeasible because the user's goals are usually unknown and hard to guess. Based on the above, it is recommended to learn neural network target estimation from off-line simulation conversations. This will eliminate the need for goal checking during online strategy learning. Using obj=subj checks will make its strategy as effective as training. However, user simulators can only provide data that approximates real users. Developing user simulators is an expensive process. In order to solve the above problems, this article describes an online active learning method in which users are asked to provide feedback, regardless of whether the dialogue is successful or not. But only when the feedback is effective, active learning will limit the feedback requirements, and the noise pattern is also introduced to explain the user's error feedback. The Gaussian process classification (GPC) model uses robust mode to model the feedback of noisy users. Because the GPC runs in a fixed-length observation space, its conversation length can vary, and an embedded function based on a recurrent neural network (RNN) is used to provide a fixed-length conversational representation. In essence, the proposed method learns dialogue strategies and online feedback simulators and is directly applicable to real-world applications. The rest of this article is organized as follows. The next section describes related work. The proposed framework will be introduced in section 3. This includes strategy learning algorithms, the creation of dialog tessellation functions, and active feedback patterns that are sorted by user. Section 4 presents the evaluation results of the proposed method in the context of British Cambridge restaurant information. We first analyze the dialogue mosaic space in depth. When it conducts dialogue strategy training with real users, the results will be presented. Finally, the conclusion is in part 5. Since the 1990s, the dialogue assessment has been an active research area and put forward the PARADISE framework. In this framework, the linear functions completed by the task and all kinds of dialogue features, such as dialogue duration, will be used to guess user satisfaction. degree. This assessment method can be used as a feedback function for learning conversational strategies. However, it needs to be pointed out that, when interacting with real users, tasks are rarely completed and questions about the accuracy of model theory are also raised. In the given annotation-to-discussion corpus, some methods have been used in the learning of dialog feedback patterns. Yang et al. use collaborative filtering to infer the user's preferences. The use of reward plasticity has also been studied, to enrich the feedback function for accelerated dialogue strategies. At the same time, Ultes and Minker showed a strong correlation between the satisfaction of expert users and the success of the dialogue. However, all of these methods assume that reliable dialogue annotations are available, such as expert ranking, but in practice it is very rare. One effective way to mitigate the impact of annotation errors is to rank the same data multiple times, and some methods have evolved to guide the annotation process with uncertain patterns. Active learning is quite useful in making decisions when an annotation is required. It is often used when using the Bayesian optimization method. Based on this, Daniel et al. use pool-based active learning methods for robotic applications. They asked users to provide feedback based on the information they currently collected and showed the effectiveness of this method. Rather than explicitly setting the reward function, the inverse RL (IRL) aims to recover potential rewards from good behavioral demonstrations, and then learn strategies that can maximize rewards. The IRL was introduced for the first time in the SDS. In this process rewards were inferred from human-to-human conversations and were imitated in the corpus. The IRL was also studied in the Wizard-of-Oz setup; Rojas Barahona and Cerisara understood the output based on lectures of different noisy grades, and the human expert would act as the dialogue manager to select each system. However, this method is very expensive and there is no reason to assume that one person performs best, especially in a noisy environment. Because human beings perform better than giving absolute evaluations in giving relevant evaluations, another related research mainly focuses on the method of RL preference. In the Sugiyama et al. study, users are asked to sort through different conversations. However, this process is also very expensive and does not have good practical applications. The proposed framework is described in Figure 2. It is divided into three parts: dialogue strategy, dialogue tessellation function and active reward mechanism for user feedback. When each conversation ends, it extracts a set of horizontal features ft and mosaics them into the tessellation function σ to obtain a dimensionally fixed dialog representation d, which represents the input space for the reward model R. This reward is modelled on Gaussian process. Each input point evaluates the success of the task and also evaluates its uncertainty. Based on this uncertainty, R will decide whether it is necessary to ask the user's feedback. Then return the enhanced signal to update the conversation strategy. The strategy is calculated by the GP-SARSA algorithm. GP-SARSA also uses the Gaussian process to provide an online example of effectiveness-enhanced learning, using a minimum number of instances for the evaluation of sparse functions. The quality of each dialogue is determined by the cumulative reward. Each dialogue will generate a negative reward (-1). The last reward is 0 or 20 is determined by the reward model's evaluation of the completion of the task. It is important to note that the key to learning the reward mode is noise robustness when the user is the supervisor and the session strategy can be online at the same time. Active learning is not an important part of the framework, but it can reduce the impact of monitoring mechanisms on users in practice. One component of the proposed method is used to train the use of the tessellation function in advance, and offline training is performed in the corpus instead of manual design. Modeling user feedback that is not the same as the length of the conversation, the tessellation function will have a fixed spatial dimension for each function. The use of embedded functions has gained attention in recent word representations and has improved the performance of some natural language processing. It has also been used successfully in Machine Translation (MT), which uses RNN decoding and encoders to perform fixed-length vector positioning for phrases of different lengths. Similar to MT, dialog tessellation allows utterances of different lengths to be positioned on a fixed-length vector. Although the application here is to create a dimensionally fixed output space for GPC task success classifiers, it is worth noting that this will potentially increase the number of tasks that depend on classification and aggregation. The embedding function of the pattern structure is shown on the left side of FIG. 2 , and the fragment level ft is extracted from the dialogue and encoded as input features. In our proposed model, the decoder is a bidirectional long-term short-term memory network (BLSTM). LSTM is a recursive unit of a Recurrent Neural Network (RNN) and is a method introduced to solve and mitigate gradient disappearance problems. The input data in the two directions BLSTM decoder takes its sequence information into account, calculates the forward hiding sequence h1:T and the reverse hiding sequence hT:1, and simultaneously iterates all the input features ft,t=1,... T: Where LSTM represents the activation function. Then the dialog shows that d is calculated as the average of all hidden sequences: Where ht=[ht;ht] is a combination of two bidirectional hidden sequences. The given dialogue indicates that d is output by the encoder and the decoder is the forward LSTM (d is used as an input when t is adjusted every time t produces an adjustment sequence f1:T). The training objective of the encoder-decoder is to minimize the mean squared error between the prediction f`1:T and the output f1:T (also as input): Where N is the number of training sessions, ||·||2 represents l2-norm. Since all the functions used in the decoder and the encoder are not the same, a stochastic gradient descent (SGD) can be used to train the model. The dialogue representation based on the LSTM unsupervised embedding function was subsequently used to review the reward model introduced in Section 3.2. Figure 2: Schematic diagram of the system framework. The three main system components: dialogue strategies, dialogue embedded creation, and reward models based on user feedback, as described in § 3. The Gaussian process is a Bayesian nonparametric model that can be used for regression or classification. It is particularly attractive because it can learn from a small observation (using a kernel function defined correlation), which provides the uncertainty of the assessment. In the context of the spoken dialogue system, it has been successfully used for RL strategy optimization and IRL reward function regression. Here, we propose a successful modeling dialogue like the Gaussian Process (GP). This involves evaluating the probability of p(y|d,D) (the task success gives the current dialog representation d and pool D containing the previous classification dialogue). We disguise this as a ranking problem, where the evaluation is a binary comment y ∈ {−1, 1}—determination of success or failure. The comment y is drawn from the Bernoulli distribution with a probability of success p (y=1|d, D). The probability involves a potential function f(d|D): Rdim(d)→R, which is mapped to a unit interval by the probability function p(y=1|d,D)=Ø(f(d|D)), where Ø represents the cumulative density function of the standard Gaussian distribution. The latent function is given a GP:f(d)~gP(m(d),k(d,d')), where m(•) is the average function and k(•,•) is the covariance function. (kernel). This uses a fixed-squared-index kernel KSE. In order to calculate the "noise" in the user's assessment, it also incorporates a white noise kernel kWN: The first item is kSE, and the second item is kWN. The hyperparameters p, l, σn can be fully optimized using the gradient-based method to maximize the edge likelihood. Since Ø(·) is not a Gaussian distribution, the posterior probability p (y=1|d, D) obtained is difficult to analyze. Therefore, instead of using an approximate approach, we used Expected Spread (EP). Querying user feedback is expensive and may have a negative impact on the user experience. This effect can be reduced by using active learning information (as assessed by the uncertainty of the GP model). This ensures that user feedback is sought only when the model is uncertain about its current forecast. For current applications, a stream-based version of active learning is required. Figure 3 illustrates an example of 1 dimension. Given the marker data D, the posterior mean μ and the posterior variance σ2 of the potential value f(d) at the current dialog represent d can be calculated. Then a threshold interval [1−λ, λ] is set in the prediction success probability p()y=1|d,D)=Ø(μ/radius 1+σ2) to determine if the conversation is marked. The decision boundary implicitly considers the posterior mean and variance. When deploying this reward model in the proposed framework, the GPs previously used for f with zero-means are initialized and D={}. After the dialogue strategy π completes the segment with the user, the dialog embedding function σ is used to convert the generated dialog circle into the dialog representation d=σ(f1:T). Given d, the difference between the prediction mean and f(d|D) is determined, and the reward model decides whether or not to seek user feedback based on the threshold λ at Ø(f(d|D)). If the model is indeterminate, user feedback in the current segment d is used to update the GP model and generate an enhancement signal to train the strategy π; otherwise, the predictive success assessment of the reward model is directly used to update the strategy. This process will be performed after each conversation. Photo 3: An example of a 1 dimensional dimension of the proposed GP active reward learning model. The target application is a telephone-based spoken dialogue system for restaurant information in the Cambridge (UK) region. Mainly consists of 150 venues, each with 6 slots (attributes), of which 3 can be used by the system to constrain the search (food type, range and price range), and the remaining 3 are the nature of the message (phone number, address and zip code) ) Once the required database entity has been discovered it can be used. The core components of SDS sharing, like all experiments, include an HMM-based identifier, an obfuscated semantic network (CNET) input decoder, a BUDS belief state tracker (using dynamic Bayesian networks to generate dialogue states), and a Natural language-based templates—Describe system semantic actions as natural language response users. All strategies are trained using the GP-SARSA algorithm, and the summary action space of the RL strategy includes 20 actions. The reward given to each dialogue is set to 20×1 success-N, where N is the number of dialogs, and 1 is an indicator function of the dialog success, which is determined by different methods as described below. These rewards constitute a strengthening strategy for strategic learning. The LSTM decoding and encoding mode is described in section 3.1. It is mainly used to generate a mosaic d for each sentence. Each conversation contains the user's utterance and the system's answer. A feature vector of size 74 is extracted. This vector includes the user intent determined by the decoder, the distribution of beliefs determined by the ontology, a popular system response code, and the number of turns determined by the maximum number of turns (here 30). This eigenvector is used as the input and target of the LSTM codec mode, and its training objective is to reduce the loss of the MSE's reconstruction function. This model uses the Theano library corpora for experimentation. This corpus includes 8565, 1199,650 real users in a dialogue at the Cambridge restaurant for training, testing and testing. This corpus is collected through the Amazon Mechanical Turk (AMT) service and its employers communicate through a dialogue system. Each conversation of SGD in back propagation is used in training mode. To prevent overfitting, early blocking based on verification data is performed. To visualize the effects of embedded embedding, all 650 test conversations are transformed into an embedding function, as shown in Figure 4, and t-SNE is used to reduce the two-dimensional embedding function. For each sample of conversation, this shape implies that the conversation was successful or not, and the color also implies the length of the conversation (up to a maximum of 30). Figure 4: An unsupervised dialogue of real user data in Cambridge Restaurant indicates t-SNE visualization. The tags are sorted according to the user's subjective evaluation. From the figure we can clearly see that the color gradient from the upper left (shorter conversation) to the lower right (longer conversation) represents a positive Subj annotation. This shows that the dialogue length is one of its important features in dialog representation. At the same time, it can also be observed that those long failure dialogues (15 extra rounds) are not far apart, and most of them are in the lower right. On the other hand, some failed dialogues are scattered. In addition, the successful dialogue is shorter than 10 rounds on average. This phenomenon is consistent with the view that in a well-trained task-based system, users cannot fully engage in long conversations. This clearly visible result indicates the potential value of the use of unsupervised dialogue embedding, as improved dialog representations seem to be relevant to most successful dialogue cases. According to the purpose of the GP reward model, the LATM codec embedding function seems to be helpful in extracting an appropriate fixed dimensional dialog representation. Given the well-trained dialog embedding function, the proposed GP reward model will operate within this input space. The system was implemented in the GPy library (Hensman et al., 2012). Based on the prediction of the likelihood of success of each new type of observable conversation, the threshold of the uncertainty region is initially set to 1 to encourage the user to ask for an annotation. After the first 50 sessions of dialogue training, the threshold is reduced to 0.85, then set the threshold to 0.85. Initially, as each new conversation was added to the training set, the hyperparameters mentioned in Eqn to define the core structure were optimized to minimize the negative consequences of marginal likelihood on the conjugate gradient. In order to avoid overfitting, after training the first group of 40 conversations, these hyperparameters will only be reoptimized for every 20 conversations. Figure 5 shows the learning curve during online strategy optimization. This curve represents the subjective success as a function of the number of training sessions. The on-line GP, Subj, off-line RNN, and Obj=Subj systems in the figure are represented by black curves, red curves, blue curves, and red curves, respectively. A light-colored area represents a standard deviation interval. In order to study the performance of our proposed online GP strategy learning framework, the performance of three other comparative systems has also been tested. Note: The manual system is not included in the comparison because its size cannot be applied to a larger area and it is more sensitive to verbal identification errors. For each system, the only difference that exists is the difference in the method used to calculate the reward: 1. The Obj=Subj system uses previous knowledge of this task, using only the training dialog. In this process, the user's subjective assessment of success is consistent with the objective evaluation of (Gasic et al., 2013). 2. The Subj system only utilizes the user's evaluation of success and directly optimizes the strategy regardless of whether the user's evaluation is accurate or not. 3. The offline RNN system uses 1K simulation data and matching Obj tags to train RNN task success predictors (Su et al., 2015a). In the process of using the Subj system assessment method, in order to focus only on the performance of the strategy, rather than focusing on other aspects of the system, such as the fluency of the response, the user is asked to answer the question: Have you found all the information you need? ? To predict the success of the dialogue. Figure 6: During online strategy optimization, the number of times each system asks the user to obtain feedback is a function of the number of training sessions. The orange line in the figure represents Obj=Subj, the Subj system, and the black line represents the online GP system. The above four systems are trained by initiating 500 dialogs online by the user selected by the AMT service terminal. Figure 5 shows the online learning curve for subjective success prediction during training. For each system, a dynamic average was calculated using a window containing 150 conversations. In the process of training each system, three different strategies are trained, and the obtained results are averaged to reduce the annoyance of the feedback information provided by the user. As we have seen, after nearly 500 dialogue sessions, the performance of the above four systems is better than the 80% subjective success predictor performance. Among them, the performance of Obj=Subj system is poor compared to other systems. This may be due to the fact that the user still predicts the outcome of the dialogue as successful, although the objective prediction results show that the conversation failed. Similar to this situation, the dialogue will be abandoned and not used for training. Therefore, in order to obtain 500 useful conversations, the Obj=Subj system requires the use of 700 conversations. However, all other learning systems use each conversation efficiently. In order to be able to study learning behavior for a longer period of time, the number of conversations needed to train online GP systems and Subj systems was expanded to 850 times. As shown in the figure, the training results for these two learning systems showed a gradual upward trend. Similar to the results obtained by Gasic et al. (2011), the Subj system is also affected by user's unreliable feedback information. First of all, in training the Obj=Subj system, the user puts all the task requirements behind him, and especially forgets to request all the required information. Second, due to insufficient attention to the feedback information provided, the feedback information provided by users presents inconsistent phenomena. From Figure 5, we can clearly observe that the performance of the online GP system has always been superior to that of the Subj system. This phenomenon may be due to the impact of inconsistent user feedback information caused by the noisy model. Of course, unlike crowd sources, true users may provide more consistent feedback, but occasional non-conformity is inevitable, and noisy models can provide the robustness of the feedback information needed. The advantages of the online GP system in reducing the number of times the system responds to the user's need for feedback information (ie, tag costs) can be seen in FIG. 6 . The black curve shows the number of subjective learning queries required during the training of the online GP system. The displayed results are obtained by averaging the three strategies. The system only needs to ask for 150 feedback information for the user to train a robust reward model. On the other hand, as indicated by the orange dotted line, the Obj=Subj system and the Subj system all require feedback from the user during the training of each conversation. Of course, when training the system online, the offline RNN system does not need user feedback information at all, as the system has the advantage of using a user simulator. However, during the training process, when the first 300 sessions of dialogue training were completed, the performance of the system was less than that of the online GP system. In order to compare the performance of various learning systems, the first part of Table 1 is the average and standard deviation of 400 to 500 conversations. During the interval between training 400 conversations and 500 conversations, the Subj system, the offline RNN system, and the online GP system had comparable training results and did not show statistical differences. Table 1 also shows the continuous training of the Subj system and the online GP system from 500 conversations to 850 conversations. The data in Table 1 also shows that the on-line GP system has significant advantages, probably because the system is more sensitive to mis-user information than the Subj system. The above results confirm the effectiveness of our proposed reward model for strategy learning. In this section, we will further study the accuracy of the model in predicting the subjective success rate. Table 2 is an assessment of the results of the online GP reward model during 1 to 850 dialogue sessions. Since 3 training models can be learned for each 850 sessions of training, a total of 2550 sessions need to be trained. In these dialogue training processes, these models require a total of 454 user inquiry feedback messages, and the remaining 2096 dialogue trainings are used for learning. This learning method relies on the prediction results of the reward model. The results shown in the table are the average of 2,096 dialogue drills. Table 1: Results of subjective assessments of the performance of the Obj=Subj system, the offline RNN system, the Subj system, and the online GP system in different online strategy learning stages. Subjectivity: The user predicts whether the dialogue is successful or not. The statistical significance of the above results was calculated using a two-tailed student t-test, where p<0.05. As we can observe, since the dialogue strategy has been improved with the increase in the number of dialogue trainings, the proportion of the dialogue success label and the dialogue failure label has become unbalanced. Since this reward model prefers to use affirmative tag data, this will impair the user's memory of failed dialog predictions. However, its accuracy also increases. On the other hand, our proposed reward model can accurately predict the success of the dialogue. Table 2: Statistical Aspects of Online GP System Forecast Results for Subj Predictive Rates Compared with other models, the main advantage of the online GP reward model is its offsetting effect on user information feedback and the effective use of user supervision measures. Since the above four systems for comparison only differ in the design of reward models, their online behaviors exhibit similarities to a large extent. Table 3 lists two examples of dialogs between the user and the online GP system to illustrate how the system operates under different noisy conditions. The table also shows the user's subjective prediction results and the prediction results generated by the online GP reward model. The tags 'n-th AS' and 'n-SEM' refer to possible assumptions made in the nth speech verifier and semantic decoder, respectively. Table 3: Examples of conversations between an online user and an assumed online GP system In this paper, we use the Gaussian process classification method and an unsupervised dialogue embedding method based on neural network to propose an active reward learning model that aims to achieve real online strategy learning in spoken dialogue systems. The model robustly simulates the inherently noisy attributes of the real user's feedback information and can achieve a stable strategy optimization effect. It also uses active learning methods to minimize the number of user feedback information queries. We found that compared with other state-of-the-art methods, the proposed model can learn strategy effectively and have higher performance. The main advantage of this Bayesian model is that its uncertainty assessment results in learning and noise processing in a natural way. This unsupervised dialog embedding function does not require labeled data during the training process, but it can provide the reward predictor with a compressed and useful input information. On the whole, the technologies developed in this paper provide the first time a practical online learning method for dialogue systems in the real world. This online learning method does not require large corpus composed of manually annotated data. Build a user simulator. Consistent with our previous work results, the reward function studied in this paper focuses on the success of the task. This reward model may appear to be too simple in business applications. In future research work, we will identify and include other dimensions of dialogue quality with human interaction experts. These information will meet the higher level of user needs. Comments by Associate Professor Li Yanjie of Harbin Institute of Technology: Optimizing the dialogue management strategy by enhancing learning methods is a very effective method, but the precise reward function is critical to optimizing the outcome. This paper uses the Gaussian process classification method and an unsupervised dialogue embedding method based on neural networks to propose an active reward function learning model. That is, when the discovery system is uncertain about the user's information, it actively asks The method collects more information to obtain an accurate reward function, thus realizing online strategy learning in the spoken language dialogue system. The system robustly models the intrinsic noise in real user feedback, enables stable strategy optimization, and uses active learning methods to minimize the number of user feedback queries, helping to enhance the user's sense of experience. Compared with other existing methods, the model presented in this paper can effectively learn conversational strategies and have higher performance. PS : This article was compiled by Lei Feng Network (search “Lei Feng Network†public number) and it was compiled without permission. More ACL related information Scan code Focus on WeChat group Binding Adapter ,Amplifier Terminal Connector,Binding Post Connectors,Spring Loaded Binding Post Changzhou Kingsun New Energy Technology Co., Ltd. , https://www.aioconn.com Online automatic reward learning for strategy optimization of spoken language dialogue system
Summary
1 Introduction

2. Related work
3. The proposed framework
3.1 Unsupervised Dialogue Mosaic Patterns
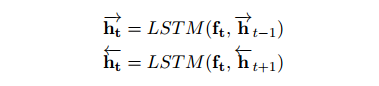
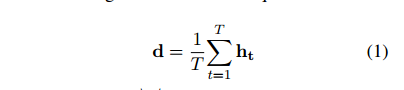
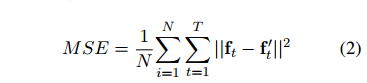
3.2. Active reward learning
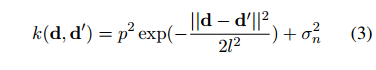
4. Experimental results
4.1 Dialogue
4.2 Dialogue Strategy Learning
4.3 Evaluating Dialogue Strategies
4.4 Evaluation of reward models
4.5 Dialogue Examples

5 Conclusion

August 02, 2024