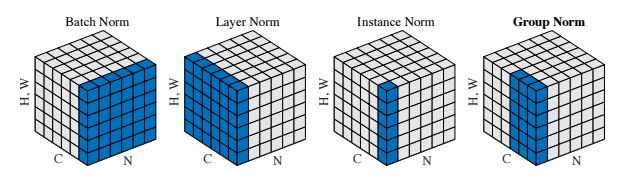
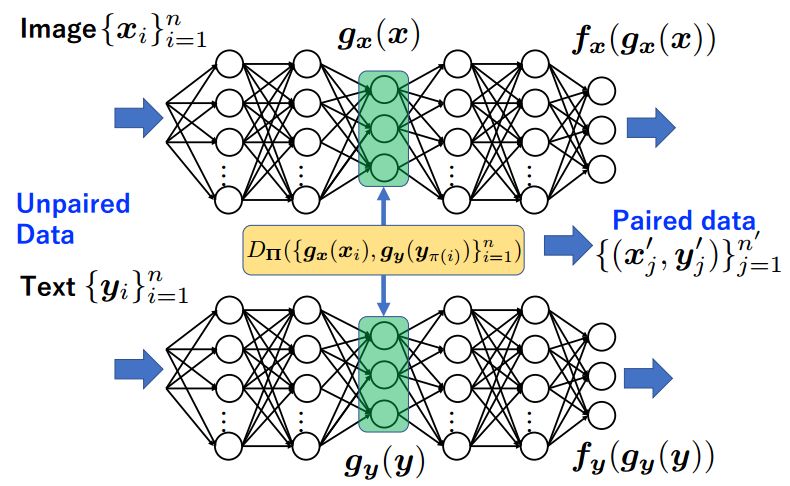
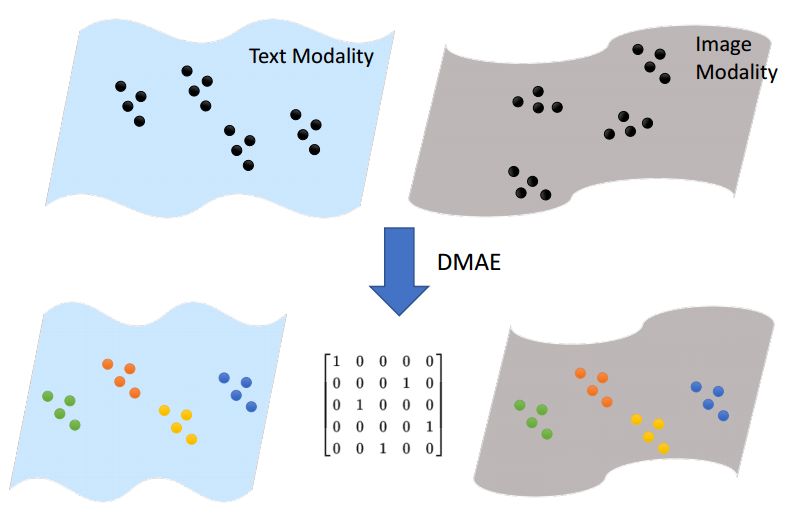
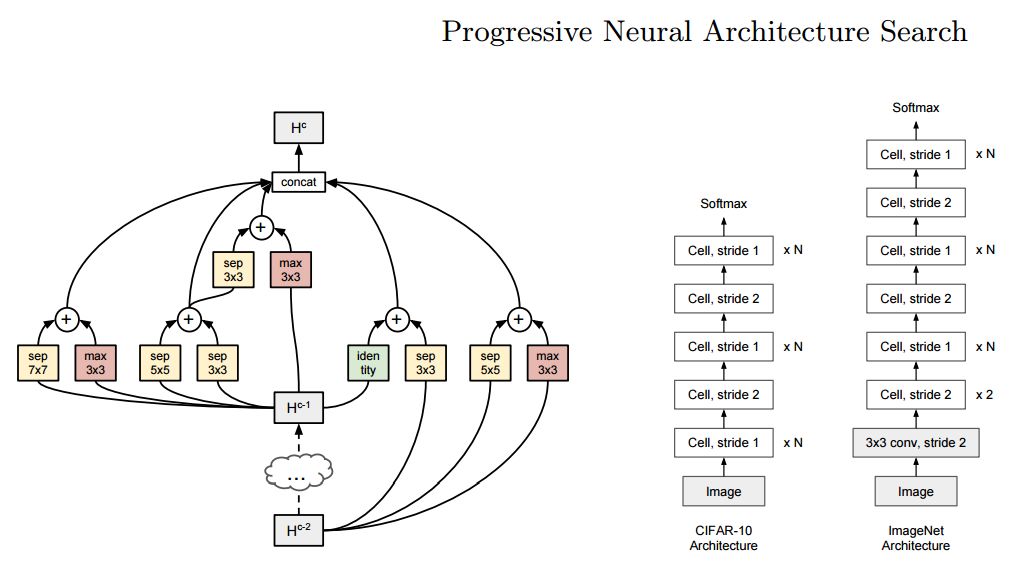
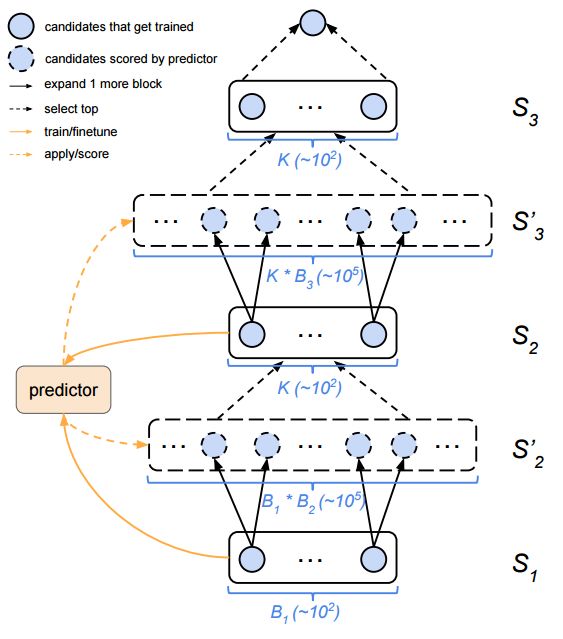
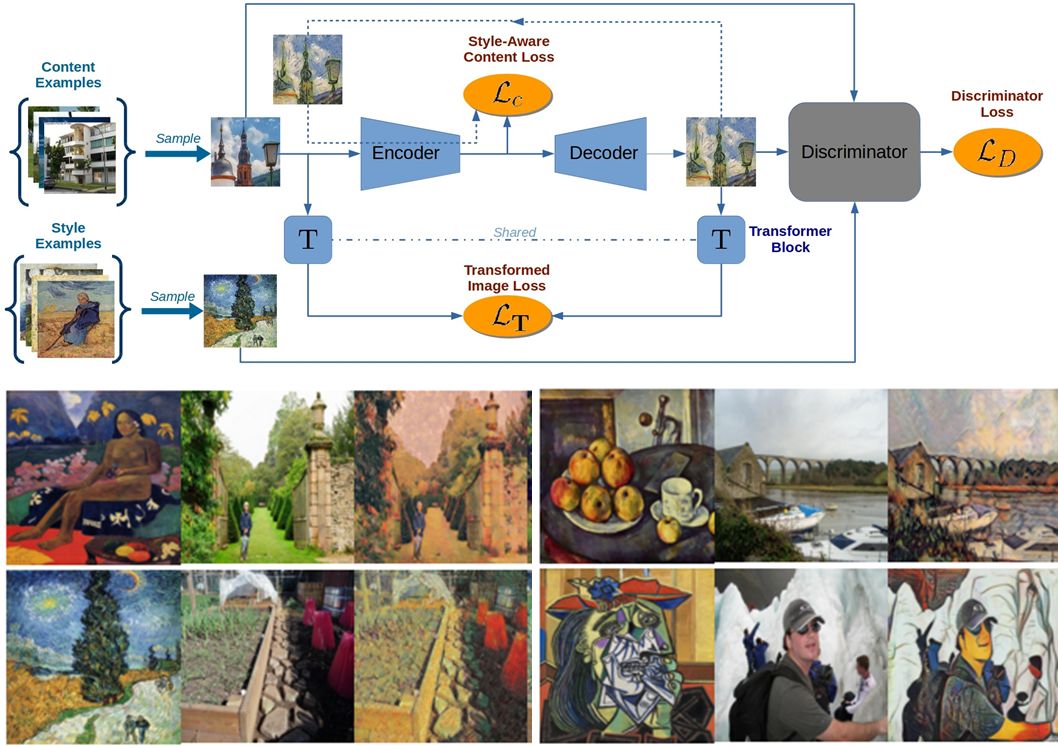
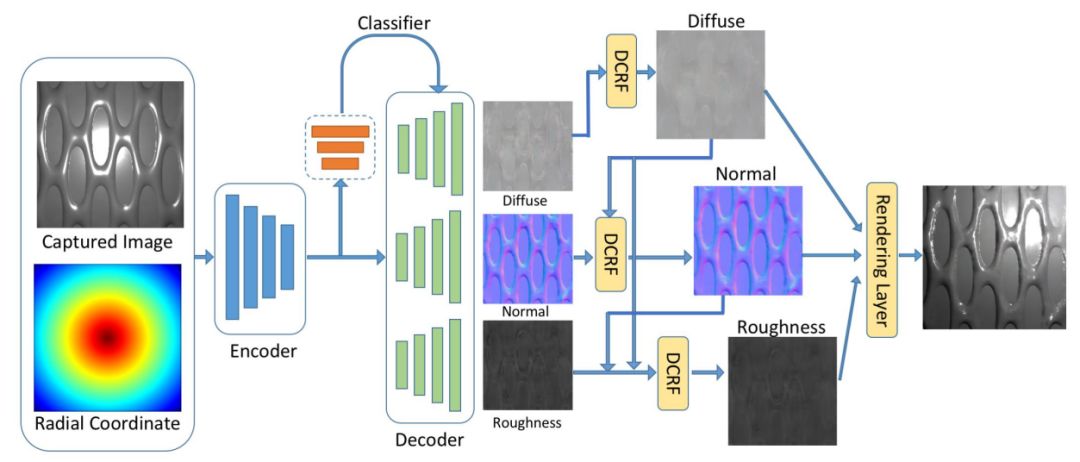
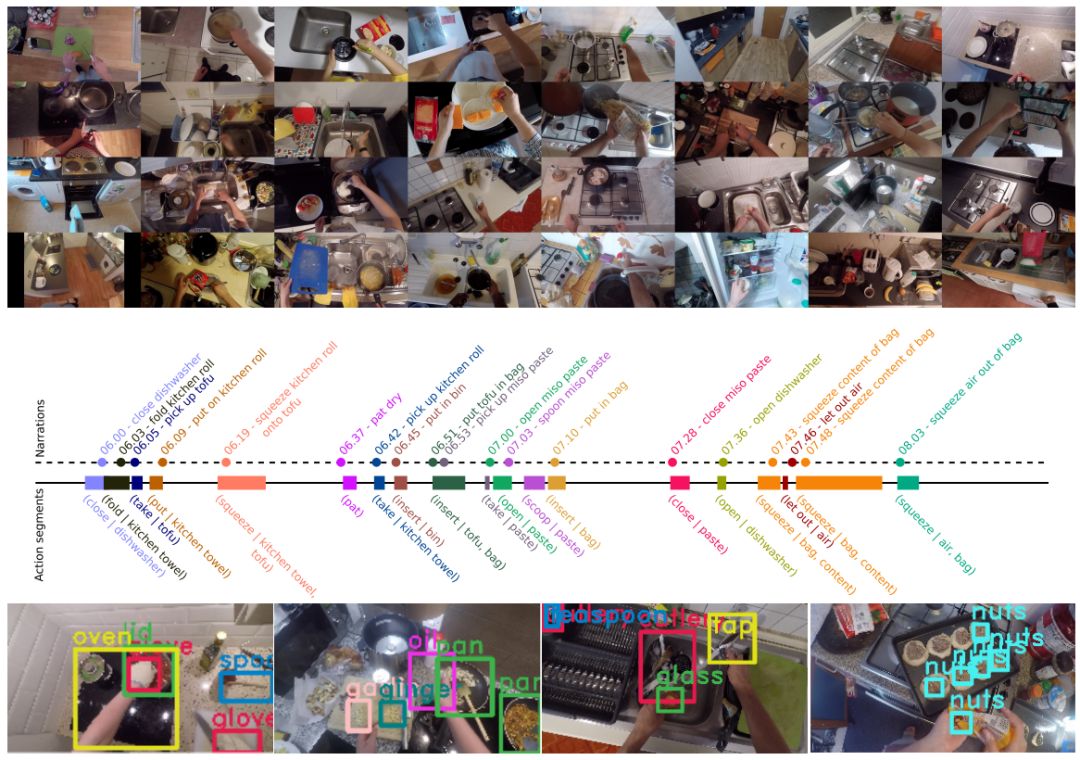
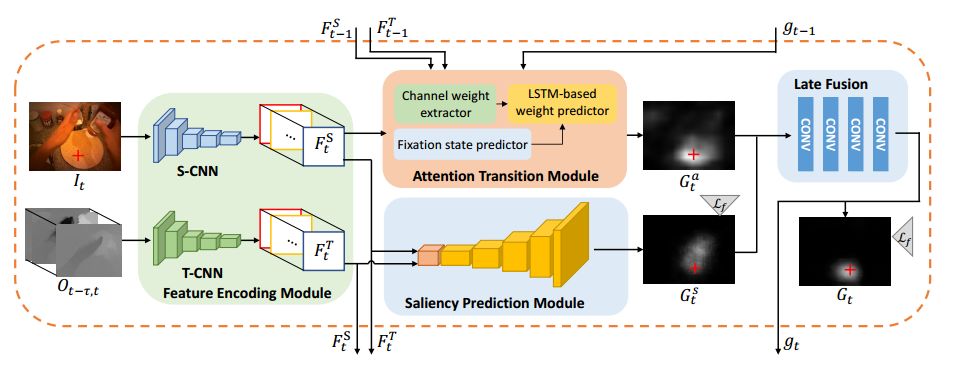
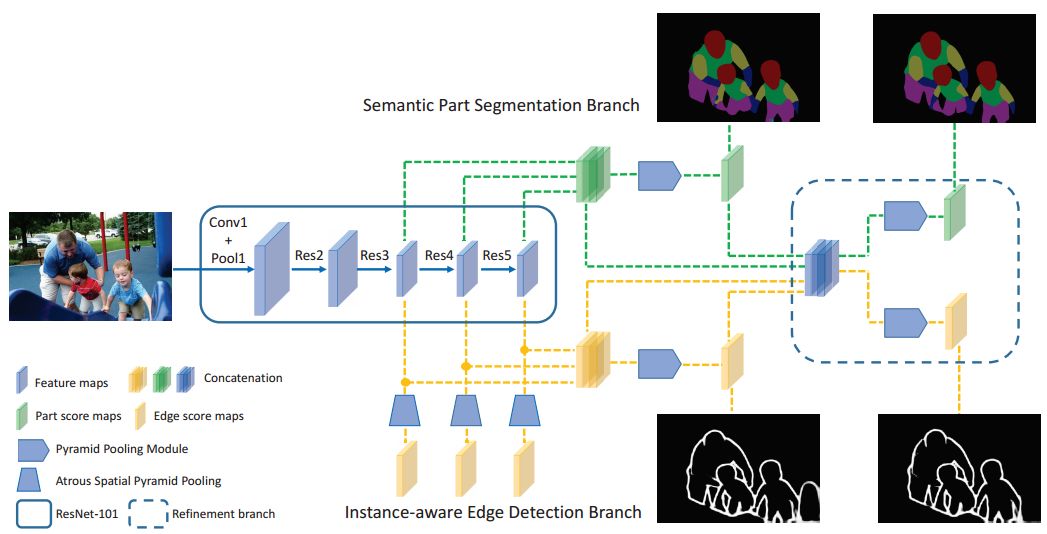
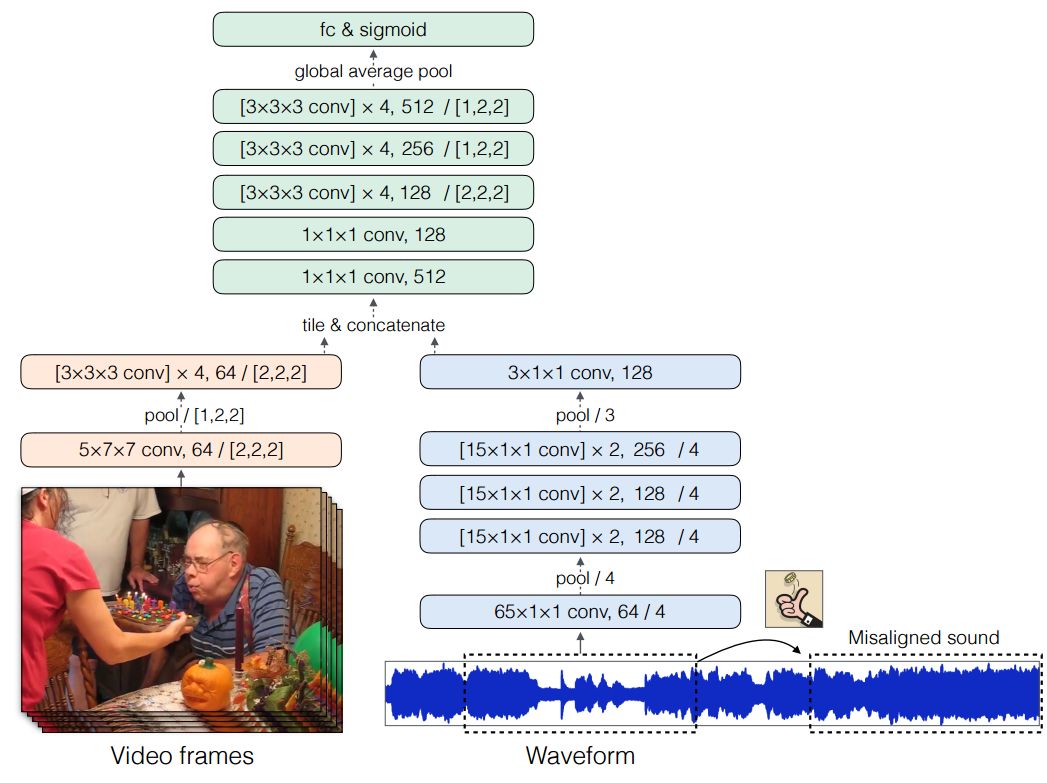
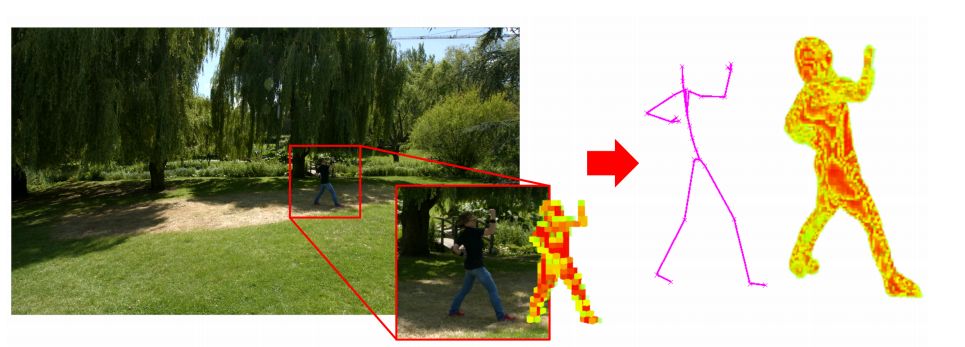
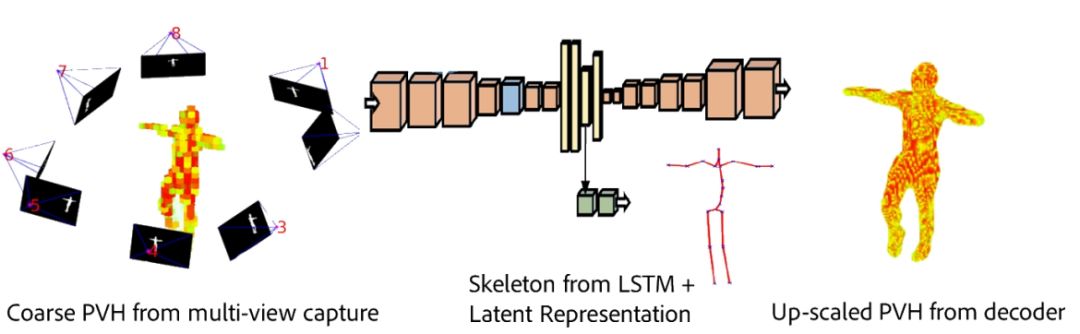
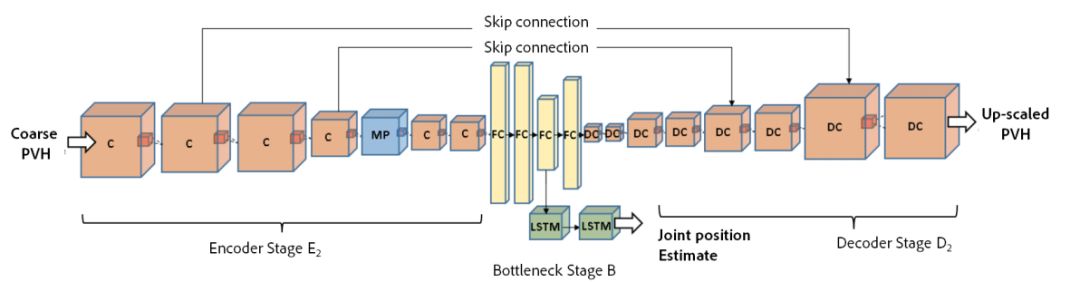
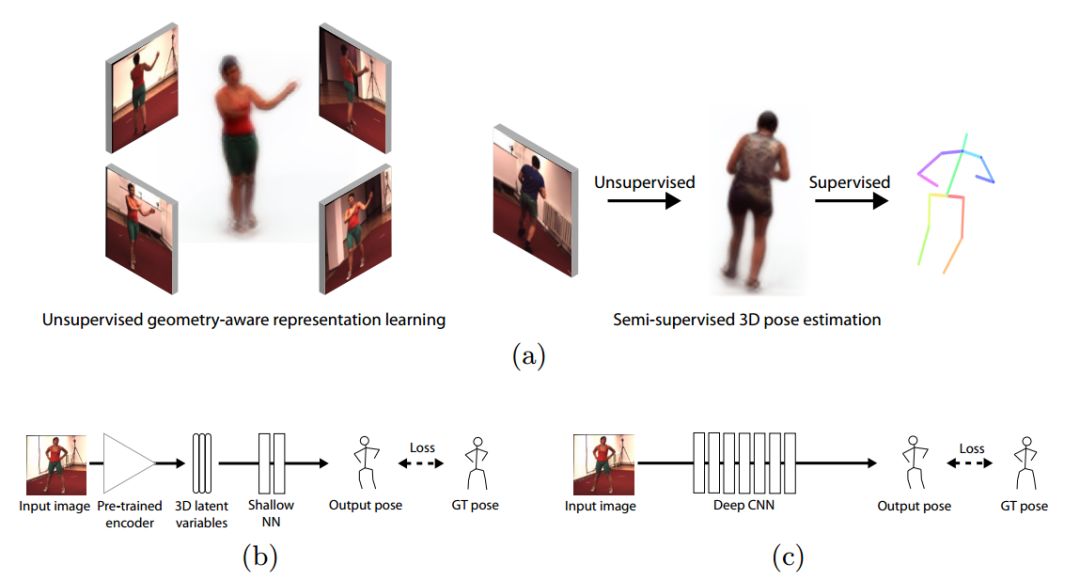
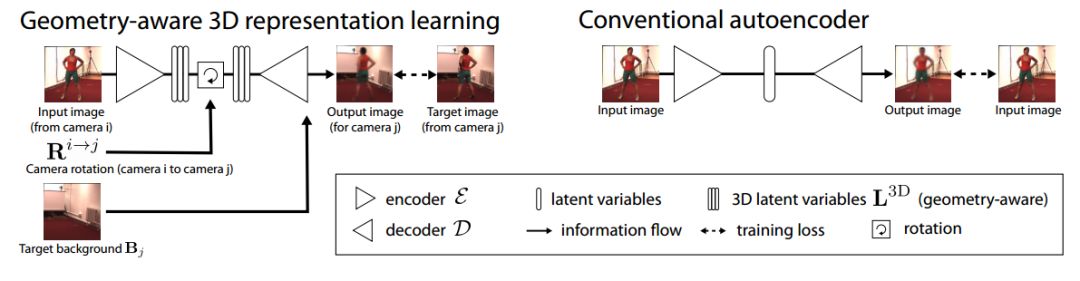
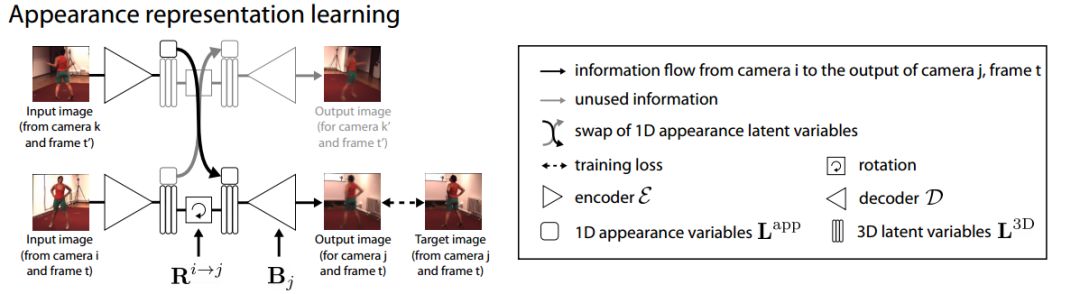
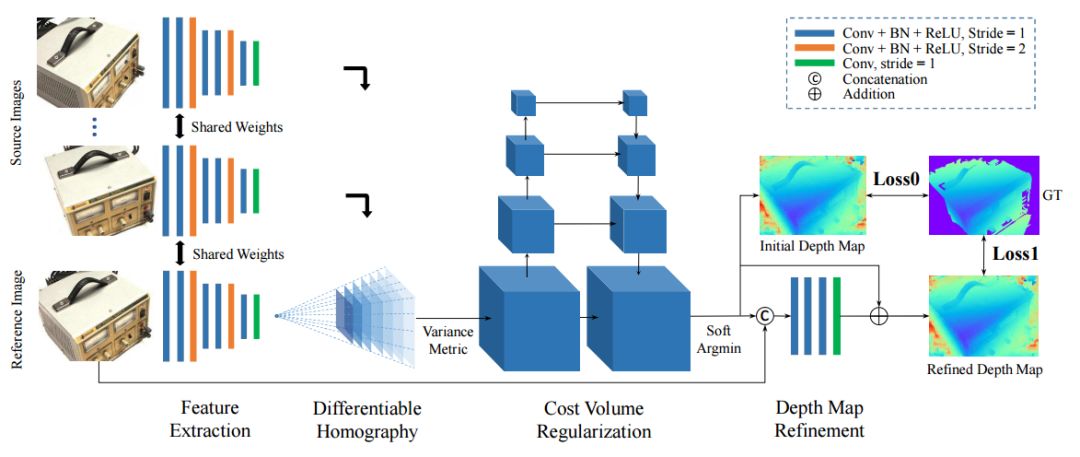
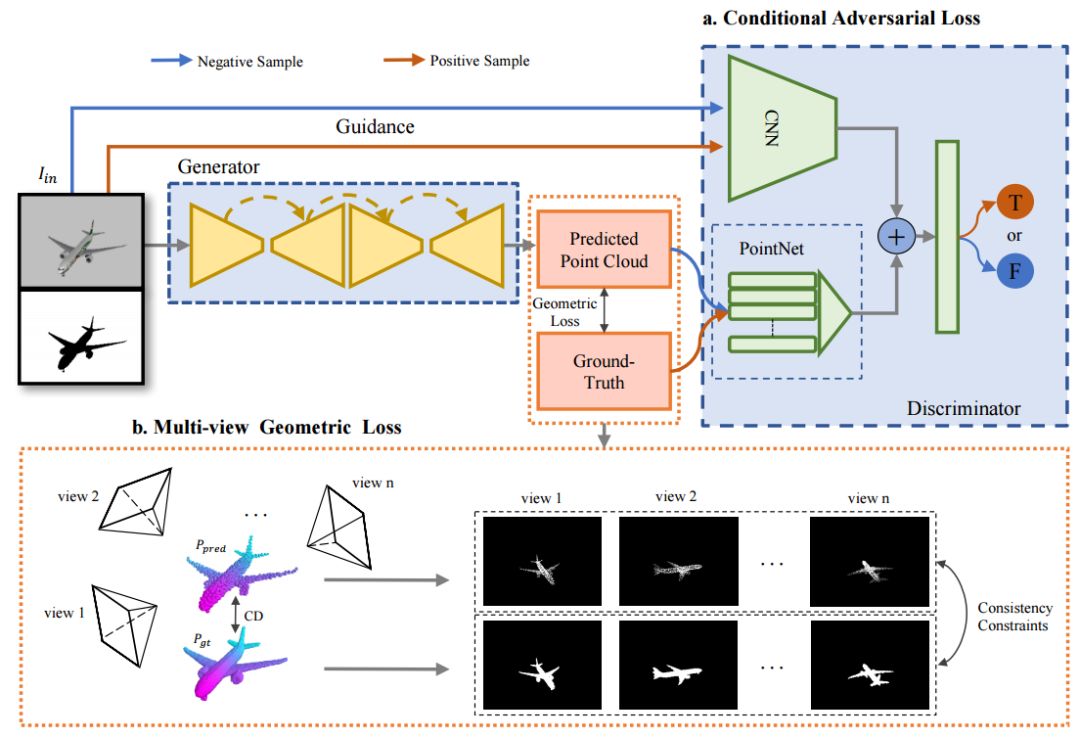
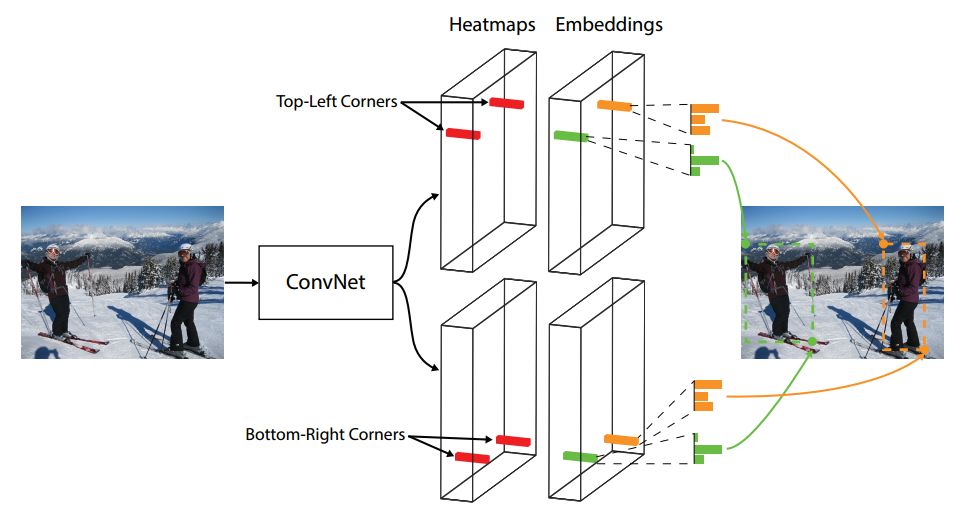
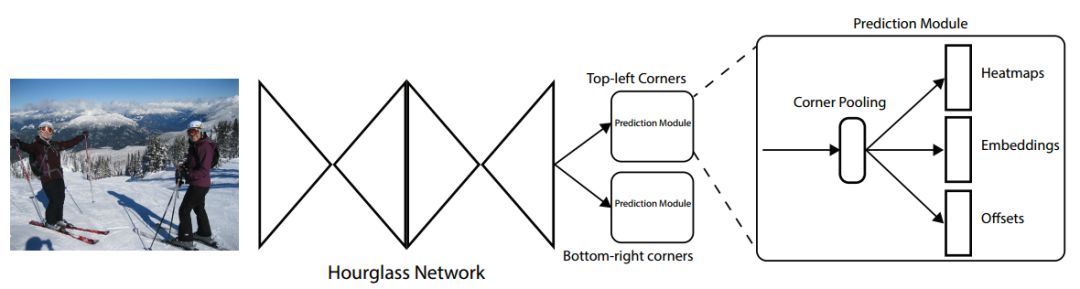
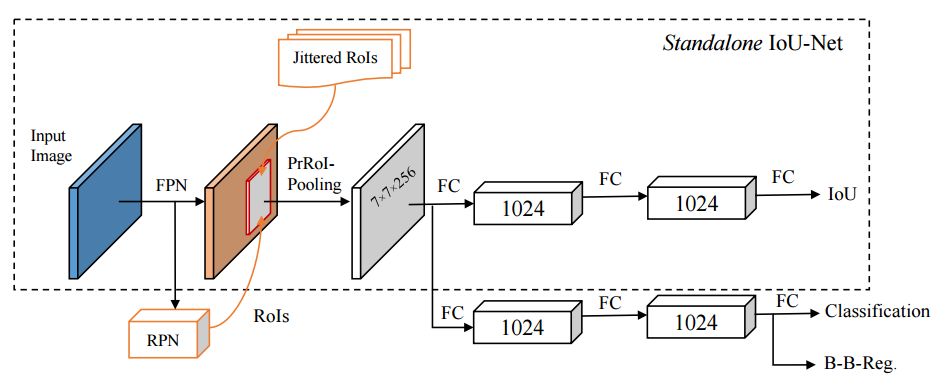
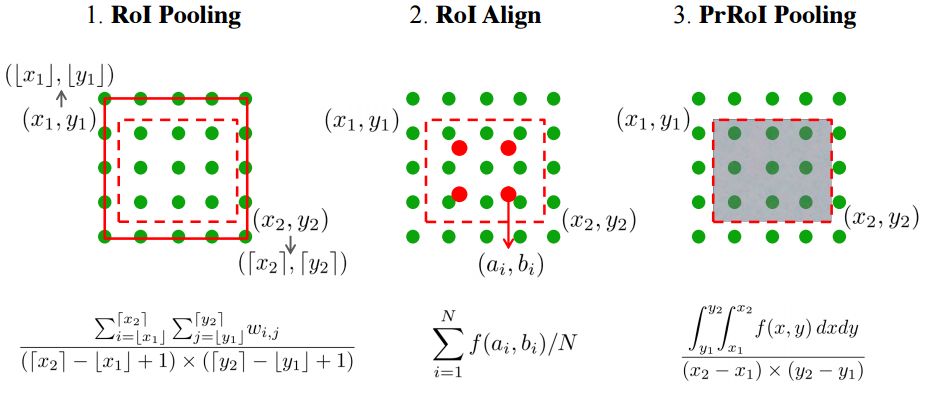
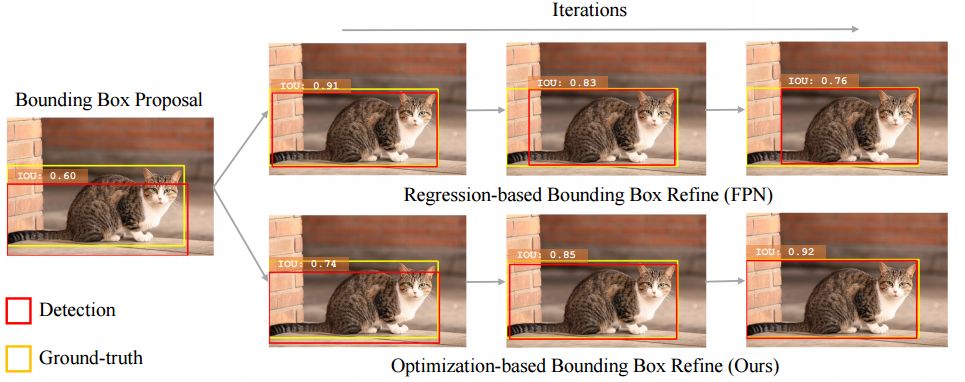
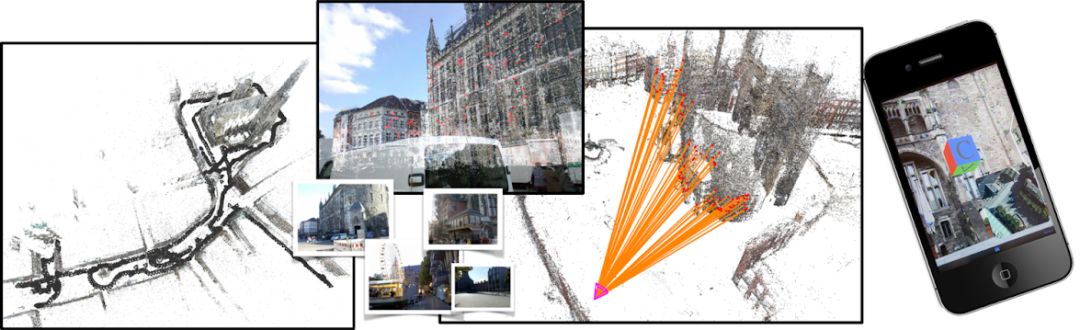
ECCV 2018, one of the three major computer vision conferences, will be held in Munich, Germany from September 8th to 14th! The conference received a total of 779 papers. At the same time, 11 tutorials and 43 workshops in various fields will be held at the conference. At the same time, excellent papers will also be presented in oral presentations at the conference. In the four-day conference schedule, there will be 59 orals reports covering various fields such as visual learning, graphic photography, human perception, stereoscopic 3D, and recognition. Let's find out first! According to the topic of the paper published on the website, it can be seen that this year's research hotspots still revolve around research methods such as learning and networking, but at the same time, research on detection, visualization and vision also occupies an important position. Next, let's take a look at the exciting research frontiers that ECCV will bring us in advance! Oral This year’s ECCV main forum arranged 12 sub-forums on different topics into the four-day meeting time on the 10th to 13th, which mainly included visual learning, computational photography, human analysis and perception, three-dimensional reconstruction, optimization and recognition, etc. . In the direction of visual learning, Group Normalization proposed by Yuxin Wu and Kaiming from Facebook to solve the problems of Batch Normalizaiton, and achieve excellent performance by grouping and normalizing different channels. There is also a deep matching autoencoder proposed by researchers from the University of Edinburgh and the Japanese Institute of Physics and Chemistry, which is used to learn a shared implicit space from unpaired multimodal data. At the same time, the progressive neural architecture search jointly researched by Johns Hopkins University, Stanford University and Google is used to learn the structure of neural networks. The optimization strategy based on the sequence model has achieved nearly five times the efficiency of reinforcement learning and evolutionary algorithms and an overall calculation improvement of 8 times. And achieved high accuracy on CIFAR-10 and ImageNet. It is worth mentioning that in addition to Liu Chenxi from Hopkins and Zoph from Google, the authors of the paper also include Li Feifei and Li Jia. According to reports, this article, together with technologies such as Neural Architecture Search with Reinforcement Learning and Large Scale Evolution of Image Classifiers, supported the development of Google AutoML. In the direction of computational photography, it includes research hotspots from point light sources, light fields, and programmable devices. Researchers from the Munich University of Technology used the characteristics of the camera's rolling shutter to optimize the back end of the direct sparse odometer, and realized the accurate VO method in near real time. Researchers from Heidelberg University proposed a style-aware content-based loss function and trained a real-time high-resolution style transfer model in conjunction with an autoencoder. Makes the produced image contains more and more natural beauty. Researchers from the University of San Diego and Adobe have proposed a bilateral reflectance function that uses a single mobile phone photo to obtain surface changes of different materials. The neural network realizes the estimation of SVBRDF, which brings new possibilities for photometric rendering. Human behavior analysis and perception include posture estimation of the human body and various parts, face and hand tracking, pedestrian recognition, behavior prediction, etc. Researchers from the University of Bristol, Catania, and Toronto gave a first-person database EPIC-KITCHENS, which is used to study human behavior and habits. This database records participants from multiple countries in the kitchen. The first-person perspective contains 11.5 million frames of images, 39,600 motion segments and 453,400 bboxes. This data set will be used in first-person object detection, behavior recognition and behavior prediction. Researchers from Hunan University and Tokyo University also proposed a model that predicts gaze attention from a first-person perspective. Researchers from Sun Yat-sen University, Shangtang and Shiyuan proposed a method of realizing example human body analysis through a partial xx network, by decomposing the example human body analysis task into semantic segmentation and merging semantic components into a certain person based on edge detection. Two subtasks are implemented. Researchers from Berkeley proposed a network that combines image and sound information in video for fusion of multi-sensor expressions, and trained a neural network that can predict whether video frames and audio are aligned in a self-supervised way, and it can be used It is used for tasks such as video sound source localization, audio-visual recognition and audio track separation. Researchers at the University of Surrey and Adobe have trained a symmetrical convolutional autoencoder to learn the encoding of skeleton joint positions and the volume representation of the body. It can accurately recover the 3D estimation of the joint position. Researchers from Lausanne Polytechnic also proposed an unsupervised 3D human pose estimation model, which can predict another perspective from a single perspective image through an autoencoder. Because it encodes a 3D geometric representation, researchers also use it for semi-supervised learning to map human poses. In terms of stereo vision 3D reconstruction, the main research focuses on geometry, stereo vision and depth reasoning. Researchers from the Hong Kong University of Science and Technology proposed to use unstructured images as input to calculate the depth map information of the reference image end-to-end. The NVSNet proposed by it encodes camera parameters into a differentiable homography transformation to obtain the frustum loss volume, and establishes the relationship between 2D feature extraction and 3D loss regularization. Finally, 3D convolution is used to regularize and regress the initial point cloud to obtain the final output result. In order to solve the problem of the mismatch between the position of the point in the point cloud prediction and the global geometric shape of the object, Hong Kong Chinese proposed the global 3D reconstruction of the point cloud under a single view with geometric counter loss optimization. Multi-view geometric loss and conditional adversarial loss are used to train the network. Multi-view geometric loss allows the network to learn to reconstruct effective 3D models from multiple views, while conditional adversarial loss ensures that the reconstructed 3D objects conform to the semantic information in ordinary pictures. In addition, it also includes Princeton's coplanar matching method, the active stereo vision network jointly completed by Princeton and Google, and the monocular sparse direct odometer based on depth prediction proposed by the Munich University of Technology. In the aspect of matching and recognition, it covers the research of target detection, positioning, texture and location refinement. Researchers from the University of Michigan proposed CornerNet, a target detection method based on key point pairs. It converts the task of target detection to the detection of the upper left and lower right corners of the bbox using a single neural network. This method eliminates the dependence on the anchor frame. And proposed a layer called corner pooling to improve the ability to locate the corner points. Eventually a mAP of 42.1% was reached on COCO. Researchers from Tsinghua University, Peking University, Megvii and Toutiao proposed a method IoU-Net to describe the reliability of framed positions in target detection, and use the positional reliability to improve non-maximum suppression in target detection to produce more accurate Forecast box. At the same time, a frame refinement method based on optimization is proposed. Researchers from the Technion-Israel Institute of Technology proposed an image transfer method based on context loss, which is suitable for unaligned data. This model defines the loss based on context and semantics. This model performs well in cartoon image simulation, semantic style transfer and domain transfer. Tutorials The tutorials of this year's ECCV also involve cutting-edge content in all aspects of the field of vision, from confrontation learning to 3D reconstruction, from pedestrian recognition to target detection. Be sure to find a tutorial you need to learn more. Among them are a series of tutorials on visual recognition and its future brought by great gods such as Kaiming, rbg and Gkioxari. There are also the theory and practice of normalization method in neural network training, the visual positioning of characteristics and learning. It also includes expression learning for pedestrian re-recognition and recognition methods based on gait & face analysis. It also includes tutorials for fast 3D perception reconstruction and understanding. For more information, please refer to, some tutorials are currently available for downloading related materials: https://eccv2018.org/program/workshops_tutorials/ Workshop Finally, let’s take a look at the workshops that are indispensable for every meeting. This year's ECCV includes 43 workshops, including 11 challenges in various fields. It is worth mentioning that many teams from China have achieved good results in many challenges. This year's workshops mainly focus on the fields of recognition, detection, automatic machines (autopilots, drones, robots, etc.), human understanding and analysis, 3D reconstruction understanding, geometry/representation learning, and early vision.
Withstand high voltage up to 750V (IEC/EN standard)
UL 94V-2 or UL 94V-0 flame retardant housing
Anti-falling screws
Optional wire protection
1~12 poles, dividable as requested
Maximum wiring capacity of 4 mm2
Feed Through Terminal Block,T12 Series Terminal Blocks,Terminal Strips Connector,Cable Connectors Block Jiangmen Krealux Electrical Appliances Co.,Ltd. , https://www.krealux-online.com







May 14, 2023