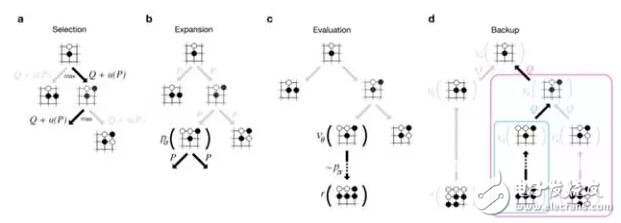
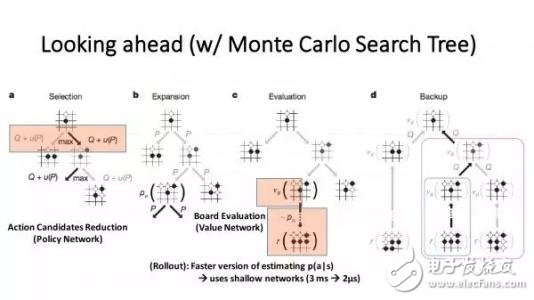
AlphaGo is the first artificial intelligence program to defeat human professional Go players and the first to defeat the World Championships in Go, developed by a team led by Google's DeepMind company, Demis Hamzabis. So what is the working principle of Alpha Dog? What are the related technologies? Let us take a look at it below. In order to cope with the complexity of Go, AlphaGo combines the advantages of supervised learning and reinforcement learning. It trains to form a policy network, takes the situation on the board as input information, and generates a probability distribution for all feasible drop positions. Then, a value network is trained to predict the self-game, and the results of all feasible positions are predicted by the criteria of -1 (absolute victory of the opponent) to 1 (absolute victory of AlphaGo). Both networks are very powerful in their own right, and Alpha Go integrates these two networks into a probability-based Monte Carlo Tree Search (MCTS), realizing its real advantages. The new version of Alpha Go produces a large number of self-game games, providing training data for the next generation version, which is a cyclical process. After obtaining the game information, Alpha Go will explore which location has high potential value and high probability according to the policy network, and then determine the optimal placement position. At the end of the assigned search time, the position most frequently examined by the system during the simulation will be the final choice for Alpha Go. After the initial exploration and process of the best, the Alpha Go search algorithm can add an approximation of human intuition on top of its computing power. The Go board is 19x19, so there are a total of 361 intersections. Each intersection has three states. You can use 1 to indicate the blackspot, -1 for white characters, and 0 for no children. Considering the time of each position, For other information such as gas in this position, we can use a 361*n-dimensional vector to represent the state of a board. We write a board state vector as s. When the state s, we do not consider the place where we can not drop the child for the time being, and the space for the next step is 361. We also use the 361-dimensional vector to represent the next step of the action, denoted as a. In this way, designing a program of Go artificial intelligence, the conversion becomes, arbitrarily given an s state, looking for the best coping strategy a, let your program follow this strategy, and finally get the largest site on the board. AlphaGo combines three block technologies: advanced search algorithms, machine learning algorithms (ie, reinforcement learning), and deep neural networks. The relationship between the three can be roughly understood as: 1. Monte Carlo Tree Search (MCTS) is a large frame In essence, it can be seen as an enhanced learning The Monte Carlo Tree Search (MCTS) will gradually build an asymmetrical tree. It can be divided into four steps and iteratively iterative: (1) Choice From the root node, that is, the situation R to be decided, select the node T that is most urgently needed to be expanded; the situation R is the first node to be inspected, and if there is an unevaluated move in the node being inspected m, then the new situation that the checked node gets after executing m is the T we need to expand; if all the feasible moves of the checked situation have been evaluated, then use the ucb formula to get a maximum ucb value. Feasible moves, and check the new situation generated by this move again; if the situation being checked is a game situation where the game has ended, then step 4 is directly executed; through repeated checks, finally one is at the bottom of the tree. The last checked situation c and one of its unrecognized moves m, go to step 2. (2) Expansion For the situation c that exists in memory at this time, add one of its child nodes. This child node is obtained by the situation c executing the move m, which is T. (3) Simulation Starting from the situation T, the two sides began to randomly drop. Finally get a result (win/lost) to update the victory rate of the T node. (4) Back propagation After the end of the T simulation, its parent node c and all its ancestors in turn update the victory rate. The victory rate of a node is the average victory rate of all the child nodes of this node. And starting from T, it has been backpropered to the root node R, so the victory rate of all nodes on the path will be updated. After that, start again from the first step and continue to iterate. As the situation of adding more and more, the victory rate of all the child nodes of R is more and more accurate. Finally, choose the move with the highest rate of victory. In practical applications, mcts can also be accompanied by a lot of improvements. The algorithm I describe is the most famous uct algorithm in the family of mcts. Nowadays, most famous ai have a lot of improvements on this basis. 2. Reinforcement Learning (RL) is a learning method used to enhance the strength of AI. 2. Reinforcement learning (RL) is a learning method used to enhance the strength of AI. Reinforcement learning is developed from theories of animal learning, parameter disturbance adaptive control, etc. The basic principles are: If a certain behavioral strategy of the Agent leads to a positive reward (enhanced signal), then the trend of the Agent to generate this behavioral strategy will be strengthened. The goal of the Agent is to find the optimal strategy in each discrete state to maximize and reward the desired discount. Reinforcement learning regards learning as a process of tentative evaluation. Agent selects an action for the environment. After the environment accepts the action, the state changes, and at the same time, an enhanced signal (a reward or punishment) is sent to the Agent. The agent re-intensifies the signal and the current state of the environment. Choosing the next action, the principle of choice is to increase the probability of being positively strengthened (award). The selected action not only affects the immediate enhancement value, but also affects the state of the environment at the next moment and the final enhancement value. Reinforcement learning is different from supervised learning in connectionist learning, mainly in the teacher's signal. The reinforcement signal provided by the environment in reinforcement learning is an evaluation of the quality of the action produced by the agent (usually a scalar signal) instead of Tell the Agent how to generate the correct action. Since the external environment provides very little information, the Agent must learn on its own experience. In this way, the Agent gains knowledge in an environment of action-one evaluation and improves the action plan to adapt to the environment. The goal of intensive learning system learning is to dynamically adjust parameters to achieve the maximum boost signal. If the r/A gradient information is known, the supervised learning algorithm can be used directly. Since the action A generated by the enhanced signal r and the Agent has no explicit functional form description, the gradient information r/A cannot be obtained. Therefore, in the reinforcement learning system, a certain random unit is needed. Using this random unit, the Agent searches in the possible action space and finds the correct action. 3. Deep Neural Network (DNN) is a tool used to fit situation assessment functions and strategy functions. Deep neural networks, also known as deep learning, are an important branch of artificial intelligence. According to the definition of McCarthy (the father of artificial intelligence), artificial intelligence is the scientific engineering of creating intelligent machinery like humans. By comparing the predicted value of the current network with the target value we really want, and then updating the weight matrix of each layer according to the difference between the two (for example, if the predicted value of the network is high, adjust the weight to make it predict lower , constantly adjust until the target value can be predicted). Therefore, it is necessary to first define "how to compare the difference between the predicted value and the target value", which is the loss function or the objective function (lossfuncTIonorobjecTIvefuncTIon), which is an equation for measuring the difference between the predicted value and the target value. The higher the output value (loss) of lossfuncTIon, the greater the difference. The training of the neural network becomes the process of reducing the loss as much as possible. The method used is Gradientdescent: the loss is reduced by moving the loss value in the opposite direction of the gradient corresponding to the current point. How much is moved at a time is controlled by the learning rate. None of these three technologies is the technology pioneered by the AlphaGo or DeepMind team. But a strong team puts these together and works with Google's powerful computing resources to make a historic leap. This disposable pod device is powered by an integrated built-in 850mah batterypre-charged with 5% nicotine strengthe-iuice.And the 5ml e-iuice
·15 Different Flavor
800mAh mesh coil vapes,Yuoto Smart Pro Disposable Vape Kit,Yuoto Smart Vape Kit,YUOTO SMART PRO 1500puffs Shenzhen Kester Technology Co., Ltd , https://www.kesterpuff.com
capacity can provide about 1500 puffs of vaping experience,which can always meet your needs.This disposable pod device adopts an integrated design,which is very convenient to carry and does not require any buttons to be pulled, which can avoid accidental ignition and oil leakage.This disposable pod device has up to 15 flavors for you to choose from. Each flavor will bring you the ultimate taste experience!
Features
·1500 Puffs Wonderful Tastes
·850mAh Built-in Battery Capacity
.5% of Nicotine content
·Pre-install 1.6ohm Coil
·Large 5ml Pod Capacity

January 14, 2023