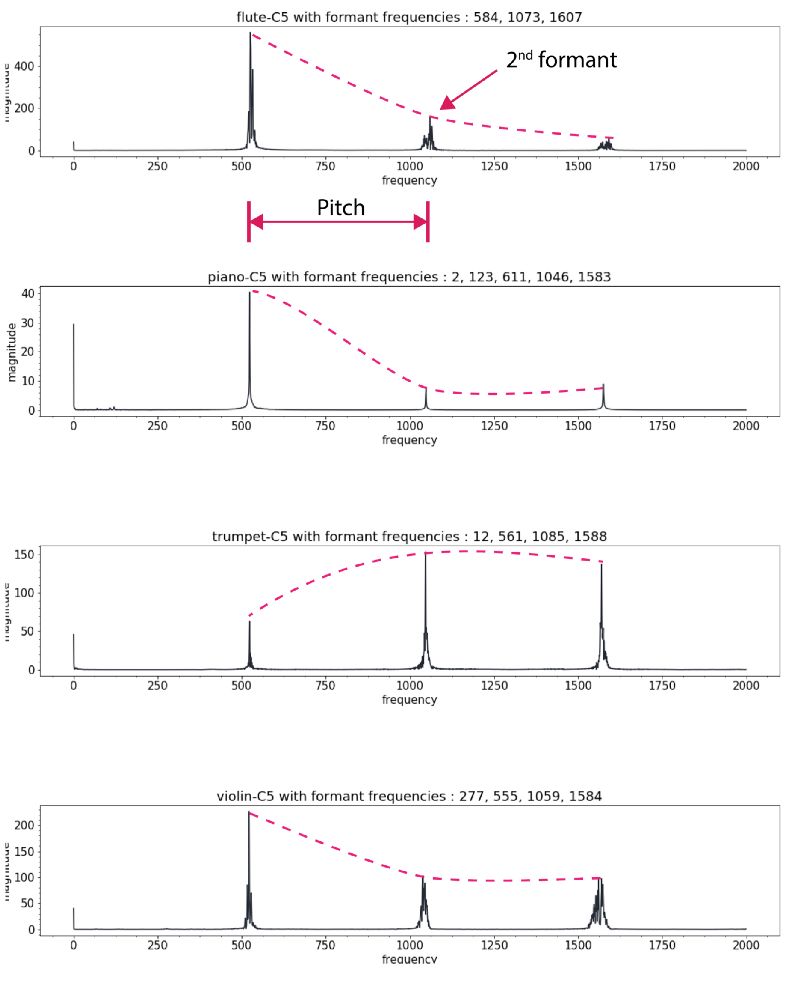
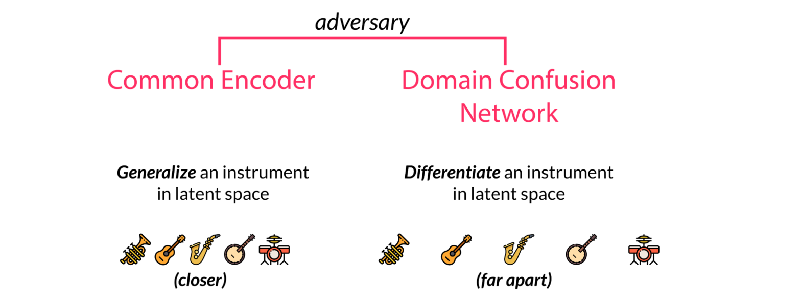
Facebook published an article called "A Universal Music Translation Network" at the end of last month (the original link is at the end of the article), detailing how to use unsupervised learning to achieve the conversion between musical instruments, genres and styles between different music. I believe my friends have more or less understood this paper. But how does this process work from a musician's perspective? This article will lead us from four different levels to understand the method described in this paper in a more in-depth way, and see what magical power converts the melodious flute to the piano. level-0: novice For novices who want to quickly achieve style conversion, Fourier transform will be a good method. Using spectrum analysis will quickly find the corresponding chords and notes and play them out on new instruments. In fact, the traditional processing method provides a series of such means: through the decoder and the intrinsic musical instrument-based instrument normalization method or polyphony method to achieve. Each instrument has a unique set of notes and temporal transient characteristics, but the difficulty is that even for a single instrument, its spectral envelope does not obey the same peak mode at different pitches. At the same time, there are different harmonic and harmonic frequencies to be processed. All of this makes it very difficult for music to change styles between different instruments. level-1: Deep learning students If you have a little music theory foundation, you can use the CNN model to learn the expression and transcription of music through the label generated by MIDI format music. MIDI is a kind of digital music commonly used in synthesizers. Every key pressed or raised means an event is triggered. The transcription of polyphony piano music can be achieved through data sets like MAPS. level-2: How will NLP scholars deal with it? The most likely method used by NLP scholars should be the sequence to sequence model, but this method needs to track the pronunciation sequence of the original instrument and the target instrument at the same time. level-3: Direct learning conversion and neighborhood normalization For very good musicians, they will understand that the nuances of each instrument cannot be captured by MIDI, and this problem is the innovation in the Facebook article. The researchers borrowed from wavenet's autoregressive architecture and made full use of it to convert this problem into a similar question of "what is the next note", thereby turning it into an unsupervised problem to solve. Wavenet essentially uses the convolution that expands with the learning process to get an increased receptive field, so that you can get better prediction results and hidden spaces that contain more rich features. These features capture the essence of human voice and instrument sound, just like the image features extracted from cnn. At this time, if you want to learn an autoregressive model to predict the next tone of the piano, you only need to learn a pair of wavenet encoder and decoder. The encoder will project the original music sequence into the hidden space, and the decoder will try its best to understand the value in the hidden space and decode it into the next value of the next sequence. Is n’t it wonderful? If a model can encode a piano but decode it into other instruments, can it be used to convert music between different instruments? This is the effort of FacebookAI researchers. They use the same encoder to encode multiple musical instruments, and then use different decoders to decode different musical instruments, and realize the style conversion between multiple musical instruments. So how does it work? Let me take a closer look below. Sharing the same decoder among multiple instruments will force this decoder to learn the same features between music. But for the decoder, we need to tell it what instrument it is and what the target domain needs to be decoded. This requires training special decoders for different instrument domains. The thesis uses an adversarial method to achieve this goal. Because the common latent space hopes to find common features while ignoring the particularity of each instrument, the confusion matrix hopes to segment different expressions in common features and achieve different category features as much as possible. Through the confrontation between special and general, two powerful encoding and decoding models are obtained. It is worth noting that if you want to obtain two codec models with excellent performance at the same time, you need to carefully choose regularization coefficients to achieve. Let's take a look at the loss function of this model. The specific training process is this. First, select a sample sj in the domain of different musical instruments, and then use random tone modulation to avoid the model from brainlessly remembering the data. In the paper, the half-step transposition of -0.5-0.5 is used for 0.25-0.5s long samples, which can be expressed by O (sj, r), where r is a random seed. You may be confused about this step, but anyone who has used the Google magenta model or the instantaneous generation model will have this experience. Sometimes the model will simply repeat the sequence of the memory like a parrot learning tongue, which is blatant overfitting. Too. This is the key to the data augmentation and migration process, as well as the training of encoders for multiple instruments. The enhanced data is then converted into the hidden space through the expanded convolutional layer in the wavenet encoder, and restored to its corresponding instrument space through the corresponding decoder Dj and the next note output is predicted. The researchers calculated the loss function by cross-entropy comparing the actual next output with the predicted next output. The first item represents that the reconstruction error should be as small as possible, and the second field classification error is used to separate the features of different domains as much as possible, which is also the performance of the network in adversarial training. As an adversarial model, a supervised regular term is used to predict different domains through post-encoded feature vectors. It is called the Domain Confusion Network. In the actual working process of the network, an input symphony segment will be converted and translated into a special musical instrument, but the most amazing ability of this model is more than that. When entering a musical instrument that the model has never seen before, it still works perfectly through the automatic encoding and decoding process! This proves that the encoder in the model can indeed extract the generalized features in the music and express them in the hidden space. I have not seen this instrument in time. This is the core concept of many generative algorithms, and GANs and variational self-encoding use this idea to create a lot of fascinating work. Smart Body Fat Scales,Bathroom Scale,Bluetooth Digital Scale,Scales For Body Weight C&Q Technology (Guangzhou) Co.,Ltd. , https://www.gzcqteq.com


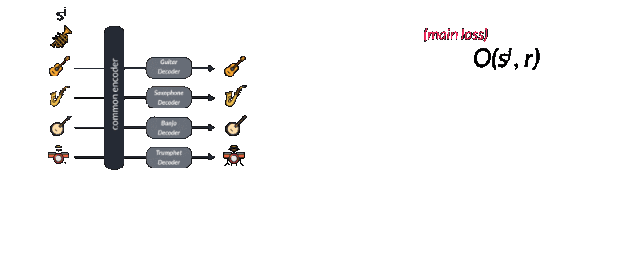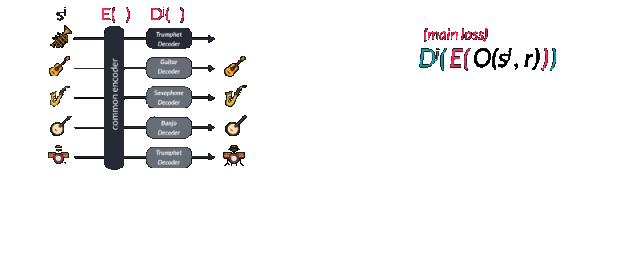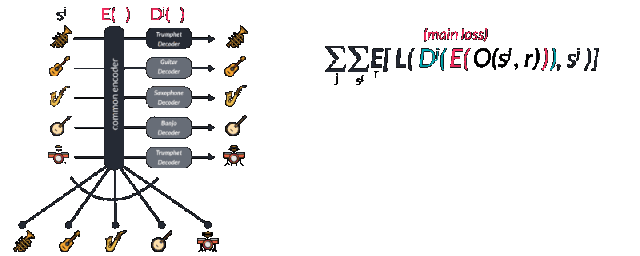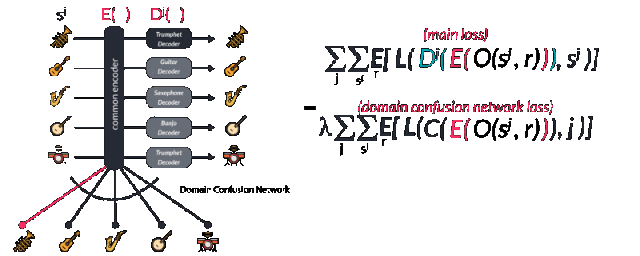

April 27, 2023