Big data is Hadoop? Of course not, but many people think of Hadoop as soon as they mention big data. Now the data scientists use massive data to create data models for the benefit of the enterprise is unimaginable, but the potential of the data has been completely tapped, does it meet people's expectations? Today, Xiaobian started to understand Hadoop from the Hadoop project. Once the big data technology enters the era of supercomputing, it can be quickly applied to ordinary enterprises. In the process of blooming everywhere, it will change the mode of business operations in many industries. But many people have misunderstandings about big data. Here is a look at the relationship between big data and Hadoop. Project Description: hadoop_storm_spark combined with the example of the experiment, simulation double 11, according to the order details, summed up the total sales, sales rankings in each region, and later SQL analysis, data analysis, data mining. The first stage (storm real-time report) - (1) User orders enter the kafka queue, - (2) Through storm, calculate the total sales volume in real time, and the sales volume of each province, - (3) Save the calculation results to the hbase database. - Phase 2 (offline report) - (1) User orders into the oracle database, - (2) Import data into hadoop via sqoop. - (3) Use mr and rdd to do etl cleaning of the original order on hadoop - (4) Create a hive table and a sparkSQL memory table. Foundation for later analysis - (5) Use HQL to analyze business indicators, and analyze user images, and the results will be stored in mysql. For web front use - Phase 3 (large-scale order ad hoc queries, and multi-dimensional queries) - (1) User orders into the oracle database, - (2) Import data into hadoop via sqoop. - (3) Write mr to load the data of hadoop onto hbase - (4) use hbase java api to achieve ad hoc query of orders - (5) Solr binds hbase, do multi-dimensional conditional query - the fourth stage (data mining and graph calculation) - (1) user orders into the oracle database, - (2) import data into hadoop through sqoop. - (3) Use mr and rdd to do etl cleaning on the original order on hadoop. In general, Hadoop is suitable for applications of big data storage and big data analysis, suitable for clusters running from thousands to tens of thousands of servers. PB level storage capacity. Typical Hadoop applications are: search, log processing, recommendation systems, data analysis, video image analysis, data storage, and more. Hadoop is just a big data processing framework and a technology. The learning threshold is slightly lower, it will be JAVA, Linux, JVM, know the basics of synchronization, communication, etc., and then learn basically no problem. Hadoop is actually a distributed file system. The data is distributed to N servers. Once the data needs to be processed, the N servers work together to aggregate the intermediate results into the final result. Of course, this requires a special algorithm, and you can no longer use the traditional algorithm, which uses the MapReduce framework. Our versatile Taobao uses hadoop. You think about the $11 billion transaction volume of the previous year, and the accumulated data is amazing. The scope of data mining is very large. This field is very hot, but it also faces very big challenges. It is closely related to machine learning and artificial intelligence. If you want to learn this, you need not only a certain foundation (such as mathematics) but also perseverance and endurance. . There are a lot of misunderstandings about what big data is and what big data can do. Here are three misconceptions about big data: 1. The relational database cannot be greatly increased, so it cannot be considered as big data technology (not right). 2, regardless of workload or specific use, Hadoop or any other MapReduce is the best choice for big data. (not right) 3. The era of graphical management systems is over. The development of illustrations will only become a barrier to big data applications. (error) Big data for the enterprise has emerged, thanks in part to the reduction in computing energy consumption and the fact that the system has the ability to perform multiple processes. And as the cost of main memory continues to drop, companies can store more data in memory than in the past. And it's easier to connect multiple computers to a server cluster. These three changes add up to big data, says Carl Olofson, IDC database management analyst. "We not only have to do these things well, but we can afford the corresponding expenses," he said. "Some supercomputers in the past also have the ability to perform multiple processing of the system (these systems are closely connected to form a cluster) but because of the use of specialized hardware, it costs hundreds of thousands of dollars or more." Now we The same configuration can be done using normal hardware. Because of this, we can process more data faster and more efficiently. " Big data technology has not been widely adopted by companies with large data warehouses. IDC believes that in order for big data technology to be recognized, the technology itself must be cheap enough, and then must meet the 2V that IBM calls the 3V standard, namely: variety, volume, and velocity. The category requirement refers to the type of data to be stored is divided into structured data and unstructured data. Volume means that the amount of data stored and analyzed can be very large. “The amount of data is not just a few hundred terabytes,†Olofson said: "It depends on the situation, because of the speed and time, sometimes a few hundred GB may be a lot. If I can complete the 300GB data analysis that took an hour to complete in one second, the result will be Big difference is big data is such a technology that can meet at least two of these three requirements, and ordinary enterprises can also deploy."
52 Jack,Professional Plastic 6p6c RJ45 ModularJack manufacturer is located in China, including Top Entry Rj45,6p6c Modular Connectors,RJ45 Connector Diagram, etc.
The RJ-45 interface can be used to connect the RJ-45 connector. It is suitable for the network constructed by twisted pair. This port is the most common port, which is generally provided by Ethernet hub. The number of hubs we usually talk about is the number of RJ-45 ports. The RJ-45 port of the hub can be directly connected to terminal devices such as computers and network printers, and can also be connected with other hub equipment and routers such as switches and hubs.
Plastic 6p6c RJ45 ModularJack,Top Entry Rj45,6p6c Modular Connectors,RJ45 Connector Diagram ShenZhen Antenk Electronics Co,Ltd , http://www.coincellholder.com
Hadoop is a distributed system architecture that processes massive amounts of data. It can be understood that Hadoop is a tool for analyzing large amounts of data, and is used in conjunction with other components to collect, store, and calculate large amounts of data. Let's take a Hadoop teaching actual combat project as an example to do a detailed analysis for Hadoop: 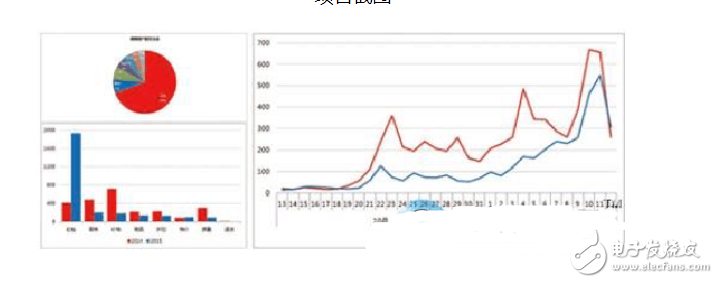


Hadoop and data mining
March 26, 2023