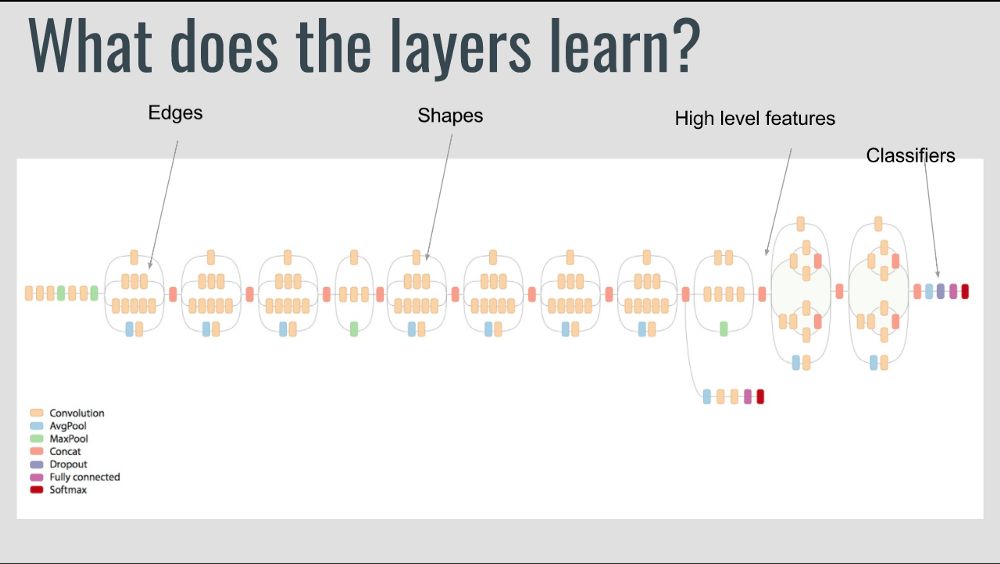
Data scientist Prakash Jay introduced the principles of migration learning, the implementation of migration learning based on Keras, and common situations of migration learning. Inception-V3 What is migration learning? Migration learning problems in machine learning, focusing on how to save the knowledge gained when solving a problem and apply it to another related and different problem. Why migrate learning? In practice, few people train a convolutional network from scratch because it is difficult to obtain enough data sets. Using pre-trained networks helps solve most of the problems at hand. Training deep network is costly. Even with hundreds of machines equipped with expensive GPUs, it takes many weeks to train the most complex models. The topology/characteristics/training methods/hyperparameters that determine deep learning are dark magics with little theoretical guidance. my experience Don't try to be a hero. - Andrej Karapathy Most computer vision problems I faced do not have very large data sets (5000-40000 images). Even with extreme data enhancement strategies, it is difficult to achieve decent precision. However, training a network of millions of parameters on a small number of datasets usually leads to overfitting. So migration learning is my savior. Why is migration learning effective? Let's take a look at what the deep learning network learns. The front layer tries to detect edges, the middle layer tries to detect shapes, and the back layer tries to detect high-level data features. These trained networks usually help solve other computer vision problems. Below, let's take a look at how to use Keras to achieve migration learning and common situations of migration learning. Simple implementation based on Keras From keras import applications From keras.preprocessing.image importImageDataGenerator From keras import optimizers From keras.models importSequential, Model From keras.layers importDropout, Flatten, Dense, GlobalAveragePooling2D From keras import backend as k From keras.callbacks importModelCheckpoint, LearningRateScheduler, TensorBoard, EarlyStopping Img_width, img_height = 256, 256 Train_data_dir = "data/train" Validation_data_dir = "data/val" Nb_train_samples = 4125 Nb_validation_samples = 466 Batch_size = 16 Epochs = 50 Model = applications.VGG19(weights = "imagenet", include_top=False, input_shape = (img_width, img_height, 3)) """ Layer (Type) Output Shape Parameter Number ================================================== =============== Input_1 (InputLayer) (None, 256, 256, 3) 0 _________________________________________________________________ Block1_conv1 (Conv2D) (None, 256, 256, 64) 1792 _________________________________________________________________ Block1_conv2 (Conv2D) (None, 256, 256, 64) 36928 _________________________________________________________________ Block1_pool (MaxPooling2D) (None, 128, 128, 64) 0 _________________________________________________________________ Block2_conv1 (Conv2D) (None, 128, 128, 128) 73856 _________________________________________________________________ Block2_conv2 (Conv2D) (None, 128, 128, 128) 147584 _________________________________________________________________ Block2_pool (MaxPooling2D) (None, 64, 64, 128) 0 _________________________________________________________________ Block3_conv1 (Conv2D) (None, 64, 64, 256) 295168 _________________________________________________________________ Block3_conv2 (Conv2D) (None, 64, 64, 256) 590080 _________________________________________________________________ Block3_conv3 (Conv2D) (None, 64, 64, 256) 590080 _________________________________________________________________ Block3_conv4 (Conv2D) (None, 64, 64, 256) 590080 _________________________________________________________________ Block3_pool (MaxPooling2D) (None, 32, 32, 256) 0 _________________________________________________________________ Block4_conv1 (Conv2D) (None, 32, 32, 512) 1180160 _________________________________________________________________ Block4_conv2 (Conv2D) (None, 32, 32, 512) 2359808 _________________________________________________________________ Block4_conv3 (Conv2D) (None, 32, 32, 512) 2359808 _________________________________________________________________ Block4_conv4 (Conv2D) (None, 32, 32, 512) 2359808 _________________________________________________________________ Block4_pool (MaxPooling2D) (None, 16, 16, 512) 0 _________________________________________________________________ Block5_conv1 (Conv2D) (None, 16, 16, 512) 2359808 _________________________________________________________________ Block5_conv2 (Conv2D) (None, 16, 16, 512) 2359808 _________________________________________________________________ Block5_conv3 (Conv2D) (None, 16, 16, 512) 2359808 _________________________________________________________________ Block5_conv4 (Conv2D) (None, 16, 16, 512) 2359808 _________________________________________________________________ Block5_pool (MaxPooling2D) (None, 8, 8, 512) 0 ================================================== =============== Total parameters: 20,024,384.0 Training parameters: 20,024,384.0 Unable to train parameters: 0.0 """ # Freeze layers that are not intended to be trained. Here I have frozen the first 5 floors. For layer in model.layers[:5]: Layer.trainable = False # Add custom layer x = model.output x = Flatten()(x) x = Dense(1024, activation="relu")(x) x = Dropout(0.5)(x) x = Dense(1024, activation="relu")(x) Predictions = Dense(16, activation="softmax")(x) # Create a final model Model_final = Model(input = model.input, output = predictions) # Compile the final model Model_final.compile(loss = "categorical_crossentropy", optimizer = optimizers.SGD(lr=0.0001, momentum=0.9), metrics=["accuracy"]) # Data enhancement Train_datagen = ImageDataGenerator( Rescale = 1./255, Horizontal_flip = True, Fill_mode = "nearest", Zoom_range = 0.3, Width_shift_range = 0.3, Height_shift_range=0.3, Rotation_range=30) Test_datagen = ImageDataGenerator( Rescale = 1./255, Horizontal_flip = True, Fill_mode = "nearest", Zoom_range = 0.3, Width_shift_range = 0.3, Height_shift_range=0.3, Rotation_range=30) Train_generator = train_datagen.flow_from_directory( Train_data_dir, Target_size = (img_height, img_width), Batch_size = batch_size, Class_mode = "categorical") Validation_generator = test_datagen.flow_from_directory( Validation_data_dir, Target_size = (img_height, img_width), Class_mode = "categorical") # Save the model Checkpoint = ModelCheckpoint("vgg16_1.h5", monitor='val_acc', verbose=1, save_best_only=True, save_weights_only=False, mode='auto', period=1) Early = EarlyStopping(monitor='val_acc', min_delta=0, patience=10, verbose=1, mode='auto') # Training model Model_final.fit_generator( Train_generator, Samples_per_epoch = nb_train_samples, Epochs = epochs, Validation_data = validation_generator, Nb_val_samples = nb_validation_samples, Callbacks = [checkpoint, early]) Common scenarios for migration learning Don't forget that the convolution features in the front layer are more general and the convolution features in the back layer are more specific to the original data set. There are four main scenarios for migration learning: 1. The new data set is small and similar to the original data set If we try to train the entire network, it can easily lead to overfitting. Because the new data is similar to the original data, we expect that the high-level features in the convolutional network are related to the new data set. Therefore, it is recommended to freeze all convolutional layers and train only classifiers (eg, linear classifiers): For layer in model.layers: Layer.trainable = False 2. The new data set is large, similar to the original data set Since we have more data, we are more confident that if we try to fine-tune the entire network, we will not lead to overfitting. For layer in model.layers: Layer.trainable = True In fact, the default value is True, the above code explicitly specifies that all layers can be trained, in order to more clearly emphasize this point. Since the first few layers detect edges, you can also choose to freeze these layers. For example, the following code freezes the first 5 layers of VGG19: For layer in model.layers[:5]: Layer.trainable = False 3. The new data set is small, but it is very different from the original data Since the data set is small, we probably want to extract features from the front layer and then train a classifier on it: (assuming you understand h5py) From keras import applications From keras.preprocessing.image importImageDataGenerator From keras import optimizers From keras.models importSequential, Model From keras.layers importDropout, Flatten, Dense, GlobalAveragePooling2D From keras import backend as k From keras.callbacks importModelCheckpoint, LearningRateScheduler, TensorBoard, EarlyStopping Img_width, img_height = 256, 256 ### Create Network Img_input = Input(shape=(256, 256, 3)) x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input) x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x) x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x) # Block 2 x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x) x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x) x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x) Model = Model(input = img_input, output = x) Model.summary() """ _________________________________________________________________ Layer (Type) Output Shape Parameter Number ================================================== =============== Input_1 (InputLayer) (None, 256, 256, 3) 0 _________________________________________________________________ Block1_conv1 (Conv2D) (None, 256, 256, 64) 1792 _________________________________________________________________ Block1_conv2 (Conv2D) (None, 256, 256, 64) 36928 _________________________________________________________________ Block1_pool (MaxPooling2D) (None, 128, 128, 64) 0 _________________________________________________________________ Block2_conv1 (Conv2D) (None, 128, 128, 128) 73856 _________________________________________________________________ Block2_conv2 (Conv2D) (None, 128, 128, 128) 147584 _________________________________________________________________ Block2_pool (MaxPooling2D) (None, 64, 64, 128) 0 ================================================== =============== The total parameter: 260,160.0 Training parameters: 260,160.0 Unable to train parameters: 0.0 """ Layer_dict = dict([(layer.name, layer) for layer in model.layers]) [layer.name for layer in model.layers] """ ['input_1', 'block1_conv1', 'block1_conv2', 'block1_pool', 'block2_conv1', 'block2_conv2', 'block2_pool'] """ Import h5py Weights_path = 'vgg19_weights.h5'# ('https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg19_weights_tf_dim_ordering_tf_kernels.h5) f = h5py.File(weights_path) List(f["model_weights"].keys()) """ ['block1_conv1', 'block1_conv2', 'block1_pool', 'block2_conv1', 'block2_conv2', 'block2_pool', 'block3_conv1', 'block3_conv2', 'block3_conv3', 'block3_conv4', 'block3_pool', 'block4_conv1', 'block4_conv2', 'block4_conv3', 'block4_conv4', 'block4_pool', 'block5_conv1', 'block5_conv2', 'block5_conv3', 'block5_conv4', 'block5_pool', 'dense_1', 'dense_2', 'dense_3', 'dropout_1', 'global_average_pooling2d_1', 'input_1'] """ # List the names of all layers in the model Layer_names = [layer.name for layer in model.layers] """ # Extract model weights for each layer in the `.h5` file >>> f["model_weights"]["block1_conv1"].attrs["weight_names"] Array([b'block1_conv1/kernel:0', b'block1_conv1/bias:0'], Dtype='|S21') # Assign this array to weight_names >>> f["model_weights"]["block1_conv1"]["block1_conv1/kernel:0] # List Weights Storage Tier Weights and Offsets >>>layer_names.index("block1_conv1") 1 >>> model.layers[1].set_weights(weights) # Set the weight for a specific layer. Using the for loop we can set the weight for the entire network. """ For i in layer_dict.keys(): Weight_names = f["model_weights"][i].attrs["weight_names"] Weights = [f["model_weights"][i][j] for j in weight_names] Index = layer_names.index(i) Model.layers[index].set_weights(weights) Import cv2 Import numpy as np Import pandas as pd From tqdm import tqdm Import itertools Import glob Features = [] For i in tqdm(files_location): Im = cv2.imread(i) Im = cv2.resize(cv2.cvtColor(im, cv2.COLOR_BGR2RGB), (256, 256)).astype(np.float32) / 255.0 Im = np.expand_dims(im, axis =0) Outcome = model_final.predict(im) Features.append(outcome) ## Collect these features, create a dataframe and train a classifier on it The above code extracts the block2_pool feature. In general, because this layer has 64 x 64 x 128 features, training a classifier on it may not help. We can add some fully connected layers and then train neural networks based on them. Add a small number of fully connected layers and one output layer. Set the weight for the front layer and freeze it. Training network. 4. The new data set is very large, very different from the original data Since you have a large data set, you can design your own network or use an existing network. You can initialize the training network based on random initialization weights or pre-trained network weights. The latter is generally chosen. You can use different networks or make changes based on existing networks. Twinkle System Technology Co Ltd , https://www.pickingbylight.com
March 28, 2023