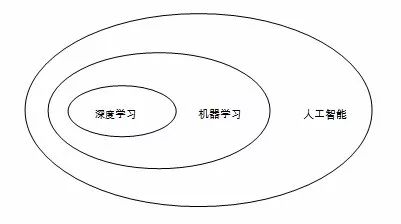
Compared with previous technological advances, the impact caused by the “Artificial Intelligence Revolution†is even greater, and its impact on economics will also be more extensive and far-reaching. The rapid advancement of artificial intelligence technology has had a major impact on all areas of the economy and society. This influence has of course also spread to economics. Many front-line economists have joined the research on artificial intelligence. Many well-known academic institutions have also organized special academic seminars. Organizational scholars have conducted special discussions on economic issues in the era of artificial intelligence. In fact, economists have not recently begun to pay attention to artificial intelligence. At the theoretical level, there are many coincidences between the study of economic decision-making issues and those of artificial intelligence, which determines that there are many cross-cutting issues in the two disciplines. Foreword Historically, economists have had at least three theoretical critiques of artificial intelligence: The first climax was the beginning of the foundation of the discipline of artificial intelligence in the 1950s and 1960s. At that time, many economists participated in the construction of this discipline. For example, Herbert Simon, winner of the Nobel Prize in Economics, was one of the founders of the artificial intelligence discipline and the founder of the "Symbol School." In his opinion, economics and artificial intelligence have a lot in common. They are all "people's decision-making process and problem solving process." Therefore, in the process of artificial intelligence research, he integrated many ideas of economics. . The second climax was at the beginning of this century. At the time, economics had made a lot of progress in game theory, mechanism design, behavioral economics, and other fields. These theoretical advances were frequently used in artificial intelligence. Recently, economists have paid attention to the issue of artificial intelligence for the third time. This climax was mainly driven by technological breakthroughs represented by deep learning. Since deep learning technology strongly depends on big data, many discussions in this round of climax focused on data-related issues. In the modeling of artificial intelligence, it also embodies the related properties of economies of scale, data intensiveness, and so on. As far as the application level is concerned, the interaction between economics and artificial intelligence is more frequent. At present, the application of artificial intelligence can be seen in such fields as financial economics, management economics, and market design. In general, the recent economics of artificial intelligence can be roughly divided into three categories: The first type of research is to treat artificial intelligence as an analytical tool. On the one hand, some technologies of artificial intelligence can be combined with traditional econometrics to overcome the difficulties of traditional econometrics in dealing with big data. Applying these new metrology techniques, economists can explore and construct new economic theories. On the other hand, the development of artificial intelligence has also facilitated the collection of new data. With the help of artificial intelligence, information such as voice and images can be easily organized into data, which provides important analytical materials for economic research. The second type of research is to use artificial intelligence as the object of analysis. From an economic point of view, artificial intelligence has a very distinct nature. First of all, artificial intelligence is a "general purpose technology" (GPT) that can be applied to various fields and its impact on economic activities is extensive and far-reaching. Now, when analyzing issues such as economic growth, income distribution, market competition, innovation issues, employment issues, and even international trade, it is difficult to avoid the effects of artificial intelligence. Second, artificial intelligence is a kind of enhanced automation. It will replace the labor force and result in biased income distribution. Third, the current development of artificial intelligence technology strongly depends on the application of big data, which determines that it has a strong scale economy and a scope economy. These two characteristics will have an important impact on issues such as industrial organization, competition policy, and international trade. . All of these features together determine that analyzing and evaluating the impact of artificial intelligence on the real economy should become an important topic in economics research. The third type of research is to use artificial intelligence as a thought experiment. As a discipline, economics is based on idealized assumptions. In reality, many assumptions are not valid, so there is a certain gap between the predictions of economics and reality. The emergence of artificial intelligence, in a sense, is to provide economists with a possible environment in line with economic assumptions. This also provides a place to test the correctness of economic theory. In this article, the author will sort out the economics literature on artificial intelligence in recent years and introduce relevant important literature. Considering that in the above three types of research, the third type of science fiction is strong and the science is relatively insufficient, so this article will not involve such research for a time. For interested readers, you can refer to Hanson (2016) and other representative literature. I. Introduction to related concepts of artificial intelligence Before we officially begin discussions on the economics of artificial intelligence, we need to first explain several concepts that are often mentioned in the literature—"artificial intelligence", "machine learning", and "deep learning." At first glance, the concept of artificial intelligence is the largest, and machine learning is a branch of it, while deep learning is a branch of machine learning (Figure 1). Figure 1: The relationship between artificial intelligence, machine learning, and deep learning In the broadest sense, artificial intelligence is "the ability of an agent to achieve its goals in a complex environment." Different scholars have different understandings about how agents should achieve their goals. Early scholars believed that artificial intelligence should imitate human thinking and action. Its purpose is to create machines that can think like humans. However, some recent scholars believe that the human way of thinking is only a specific algorithm. Artificial intelligence does not necessarily imitate humans, but it should allow agents to think and act rationally in a broader context. Some scholars represented by LeCun and Tagmark even believe that blindly imitating the human brain will only restrict the development of artificial intelligence. Artificial intelligence includes many sub-disciplines, such as machine learning, expert systems, robotics, search, logical reasoning and probabilistic reasoning, speech recognition, and natural language processing. Machine learning is a sub-discipline of artificial intelligence and is a method of implementing artificial intelligence. It uses algorithms to parse data, learn from it, and then make decisions and forecasts on real-world events. Different from the traditional idea of ​​programming specifically to solve specific tasks, machine learning “makes computers have the ability to learn without explicit programming†and finds ways to accomplish tasks by learning a lot of data. According to the characteristics of learning, machine learning can be divided into three categories: Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Supervised learning learns a sample of labelled data to find general rules between input and output. For example, for a real estate company, they have a lot of housing properties, as well as data on housing prices. If they want to learn the data and use modeling to find out the relationship between house prices and properties of various properties, then the process is Supervise learning. There are two major algorithms for supervised learning, one is the regression algorithm and the other is the classification algorithm. The data sample that unsupervised learning faces is unlabeled. The task is to learn the data to find out the underlying hidden laws in the data. For example, art connoisseurs often need to identify the genre of famous paintings. Obviously, there will not be any clearly identified feature information in any picture, so connoisseurs can only increase the subjective experience by enjoying a large number of paintings. Over time, they will find that some painters will use some painting techniques in a fixed way. Through the identification of these techniques, they can identify the genre of paintings. In this process, connoisseurs learn unsupervised learning. Clustering algorithm The main algorithm for unsupervised learning. Reinforcement learning is performed in a dynamic environment. The learner tries to maximize the reward signal through continuous trial and error. For example, students study homework by doing exercises and each time they finish an exercise, the teacher will correct the exercises and let them know which questions are right and which are wrong. According to the teacher's corrections, students find mistakes and correct mistakes, so that the correct rate continues to increase. This process is to strengthen learning. Deep learning, which has received much attention in recent years, is a research branch of machine learning. It uses multi-layer neural networks to learn, and combines higher-level representation attribute categories or features by combining low-level features to discover distributed representations of data. Under traditional conditions, due to too little data available for learning, deep learning is prone to problems such as “overfitting†and thus affecting its effectiveness. However, with the rise of big data, the power of deep learning began to manifest itself. The rapid development of artificial technology this year has largely been driven by the development of deep learning. Second, artificial intelligence as a research tool Artificial intelligence is a powerful tool for studying economics. On the one hand, machine learning in artificial intelligence has gradually begun to integrate into econometrics and has been applied in economic research. On the other hand, technologies such as speech recognition and text processing also facilitate the collection of materials for economic research. In this section, we do not discuss the application of artificial intelligence in material collection. We only focus on the application of machine learning in economics. For this reason, "artificial intelligence" and "machine learning" can be considered synonymous in this section. (I) Influence of Artificial Intelligence on Econometrics 1. Econometrics and Machine Learning: From Isolation to Fusion There are four issues of statistical concern: (1) Prediction, (2) summarization, (3) estimation, and (4) hypothesis testing. Econometrics is a sub-discipline of statistics, so the above four issues are also the subject of concern. However, as a statistic service for economics research, econometrics has a more prominent concern about causation. Therefore, it emphasizes summary, estimation, and hypothesis testing. However, there is relatively little attention to forecasting. Emphasis on the explanation of causality issues, econometrics has paid special attention to the unbiasedness and consistency of the estimation results, and devoted much effort to solving problems such as “endogenous†that may interfere with the consistency of the estimation results. Machine learning is a more applied discipline than statistics and econometrics. The issues it focuses on are more predictions than exploration of causality. For this reason, classification models such as Decision Tree and Support Vector Machine (SVM), and Ridge Regression and LASSO, which are rarely used in econometrics, are Machine learning is used extensively. Due to the different focus of attention, the intersection between econometrics and machine learning has traditionally been very small. In some cases, there are even some contradictions between the two. An example was given by Athey (2018): Suppose we have data on occupancy rates and prices for hotels in hand. If we want to use price for pre-occupancy, the resulting model usually shows a positive relationship between occupancy and price. The reason is simple. When the hotel finds itself more popular, it tends to raise its own price. However, if we consider the question of what happens when a company cuts prices, it is a problem of causal inference. At this point, according to the law of demand, if our setup does not go wrong, the resulting model will usually show a negative relationship between the occupancy rate and the price. However, with the arrival of the era of big data, the intersection between these two disciplines began to gradually increase. On the one hand, machine learning methods have gradually demonstrated their application value under big data conditions. Traditional econometrics is concerned with small, low-dimension data. For such “small dataâ€, traditional measurement methods can better cope with it. However, when the number and dimensions of data are greatly expanded, these methods are beginning to become untenable. For example, in quantitative analysis, researchers are accustomed to adding a large number of interpreted variables to the model and then estimating them. This works well when the amount of data is small, but when the amount of data is extremely large, its requirements for computing power will be staggering. This requires that researchers must first "dimensionalize" the model and find the most critical explanatory variables. At this time, some algorithms of machine learning, such as LASSO, will play a role. On the other hand, machine learning can provide inspiration for finding causal relationships. The method of causal inference is usually applied to a well-defined model. In reality, researchers actually do not even know what model to choose. At this point, the machine learning method has its place. Varian (2014) once gave an example of the age and survival probability of a Titanic passenger. He used two methods to analyze this problem. One of them is the Logit model that is commonly used when seeking causality, and the other is the decision tree method commonly used in machine learning. According to the Logit model, there is no significant relationship between the age and survival rate of passengers. The decision tree model shows that children and senior citizens over the age of 60 will have a higher probability of survival, because the elderly and children were allowed to flee first before the Titanic sank. Obviously, in this example, the decision tree can bring us more valuable information. With this information, researchers can build further models for causal inference. It is worth noting here that if the training set is small, the machine learning algorithm can easily lead to overfitting problems, and its advantages are difficult to manifest. Under the conditions of big data, the impact of overfitting problems is greatly reduced, and the value is revealed. 2. The application of machine learning in causal inference Susan Athey, a former Microsoft chief economist and professor at Stanford University, once wrote in Science about the role of machine learning in causal inference and policy evaluation. She pointed out that machine learning, which has been more used for forecasting in the past, has a strong application prospect in the field of causal inference. Future econometricians should combine machine learning techniques with existing econometric theories. The first application of machine learning in causal inference is to replace some of the conventional methods that do not involve causality. For example, in the causal inference analysis, Propensity Score Matching is often used. The first step in using this method is to rely on nuclear estimation and other methods to calculate the propensity scores, and these estimates are difficult to perform in the case of a large number of covariates. In order to filter out useful parts among a large number of covariates, some researchers proposed to apply LASSO, Booting, Random Forest and other algorithms commonly used for machine learning to the process of covariate screening, and then use the results obtained to follow Traditional steps to match. The second application of machine learning in causal inference is the estimation of the effect of heterogeneity treatment. The causal inferences of the past are mainly carried out in the average sense. The focus of attention is the Average Treatment Effect (ATE). Although such analysis has important value, it cannot meet the needs of practical applications in many cases. For example, when a doctor decides whether to use a therapy for a cancer patient, if he only knows that the therapy can increase the patient's survival time by one year on average, it is obviously not enough. Because the effect of the same therapy on different patients is very different, when deciding whether to use the therapy, doctors need to know further what kind of symptoms the patients with different traits will have when using this therapy. In other words, in addition to ATE, he also needs to pay attention to the Heterogeneous Treatment Effect. Athey and Imbens (2015) introduced the classification and regression trees commonly used in machine learning to the traditional causal framework and used them to examine the effects of heterogeneity. They compared four different categorical regression tree algorithms—Single Tree, Two Trees, Transformed Outcomes Tree, and Causal Tree. The role of the causal tree method. Wager and Athey (2015) promoted the causal tree approach and discussed how Random Forest can be used to treat heterogeneous treatment effects. Hill (2011) and Green and Kern (2012) used another idea - the Bayesian Additive Regression Tree (BART) to examine the heterogeneity treatment effect. In a sense, it can be considered as a Bayesian version of the random forest method. However, the large sample nature of the BART method is still unclear, so its application still has some limitations. For a more detailed introduction to the application of machine learning in causal inference, refer to the review by Athey and Imbens (2016). There are two points to emphasize here. First, the intersection of causal inference theory and machine learning theory is not one-way. Some artificial intelligence experts represented by the Turing Award winner Judea Pearl believe that the reason why the strong artificial intelligence technology cannot be broken now is that the existing machine learning theory does not consider causality. If there is no causality, counterfactual analysis cannot be carried out, and the agent will not be able to cope with the complicated reality. Therefore, these scholars suggest that future machine learning should consider the results of causal inference theory and lay the foundation for automatic reasoning. Second, the fastest-growing deep learning in machine learning has so far not played a role in economics research. This may be because the learning process of deep learning is itself a black box and is not suitable for being used as a tool for causal identification. (B) Application of Artificial Intelligence in Behavioral Economics Artificial intelligence can provide a way for the study of behavioral economics. Compared with traditional economics, the research method of behavioral economics is very open. It attempts to explain the human behavior that cannot be explained by traditional economics by incorporating theories of other disciplines (such as psychology and sociology). There are many variables that may explain people's behavior. It is called a question of which variables are really useful. At this time, machine learning methods can be used to help researchers select those variables that are truly valuable. At present, there are some literatures in behavioral economics that borrow machine learning methods. For example, Camerer, Nave and Smith (2017) used machine learning methods to analyze the “unstructured bargaining†problem and used it to help find the behavioral factors that affect the outcome of negotiations. Peysakhovich and Naecker (2017) used machine learning methods to study the risk selection of people in financial markets. In addition to pointing out the application of machine learning in analysis, Camerer (2017) also contrasts machine learning with human decision making. In his opinion, human decision-making can be considered as imperfect machine learning. The behavioral deficiencies such as overconfidence, seldom correcting errors, etc. can be considered in some sense as "overfitting" problems in machine learning. From this perspective, Camerer believes that the development of artificial intelligence will help humans make more effective decisions. Third, as the research object of artificial intelligence As a new technology, artificial intelligence technology has entered all areas of economic life and has had a major impact on all aspects of production and life. At present, many literatures have analyzed these effects. In this section, we will give some brief introductions to these studies in different areas. (1) Artificial Intelligence and Economic Growth 1. Theoretical Discussion on Artificial Intelligence and Economic Growth From the perspective of theoretical sources, the discussion about the impact of artificial intelligence on economic growth is actually a continuation of the discussion on the impact of automation on economic growth. Zeira (1998) proposed a theoretical model to analyze the model of automated growth effects. In this model, an industry's products can be produced through two technologies—manual and industrial. In both technologies, manual labor requires higher labor input, but the required capital investment is even lower. Which of the two technologies is used for production depends on the level of technology. If the productivity is low, then it is more advantageous to rely more on manual technology for production. When productivity exceeds a certain critical point, it will be more cost-effective to use industrial technology instead. In this way, technological progress will have two effects: First, it will directly increase the production efficiency; second, it will realize the change of production mode through automation. There are many industries in an economy, and the critical conditions for automation of different industries are different. Therefore, the degree of productivity growth and automation will assume a continuous function relationship. When the degree of automation is high, the share of capital returns in the economy is higher, so when the economy is in the optimal growth path, the growth rate will mainly depend on two conditions: the growth rate of productivity, and the share of return on capital in the economy. , higher productivity, and higher share of return on capital will allow the economy to grow faster. Aghion et al (2017) conducted a comprehensive analysis of the possible impact of artificial intelligence on economic growth. Their analysis is based on the two effects of the “artificial intelligence revolutionâ€â€”automation and Bowmore’s disease. On the one hand, as with any other technological advancement, the application of artificial intelligence will accelerate the automation process while leading to productivity gains. This will lead to a reduction in the use of manpower in the production process, which will increase the share of the return on capital in the economy. On the other hand, the "artificial intelligence revolution" will also encounter the so-called "Baumol's disease," that is, the increase in the cost of non-automated departments, which will lead to a reduction in the share of capital return in the economy. In general, as the economy develops, the impact of backward sectors of the economy on economic development will become more important. Under this condition, the impact of "Bowmore disease" will become even more negligible. Combining the two effects, the impact of the use of artificial intelligence on economic growth will be uncertain. Although the use of artificial intelligence can certainly increase the productivity growth rate, at least in the short term, its impact on the share of return on capital is uncertain. Therefore, it is not sure how the economic growth rate will change. Under normal conditions, the return share of capital will not rise indefinitely. At steady state, it will maintain a value less than 1. At this time, the speed of economic growth will mainly depend on the rate of change of productivity. Based on this, it can be concluded that how artificial intelligence affects economic growth will mainly depend on its influence on the rate of technological progress. If artificial intelligence brings only a short-term shock, it will only produce a one-time increase in productivity, and its effect will be temporary. If the application of artificial intelligence will bring about a continuous increase in productivity, then the economic growth rate will continue to increase, resulting in "economic singularity." According to several authors, the most critical condition for the emergence of “economic singularities†is to break through the bottleneck of knowledge production. Whether this can be achieved depends mainly on whether artificial intelligence can truly replace human knowledge production. In the paper, several authors also discussed the distributional effects of growth. In their view, the application of artificial intelligence technology will lead to the growth of "technology-biased type," benefiting high-skilled workers and hurting low-skilled workers. The change in organizational structure caused by technology will reinforce this effect. Enterprises that use intensive technology will pay higher wages to employees within the company, and outsource some lower-tech production processes to lower wages. Low-skilled workers. The income distribution effect caused by these factors will not be overlooked. It is worth mentioning that in Aghion et al's (2017) discussion, a key factor in determining the impact of artificial intelligence on growth is how artificial intelligence will affect innovation and knowledge production, but several authors Did not do more analysis. Agrawal et al (2017)'s paper complements this. This paper draws lessons from Weitzman's (1998) view that the process of knowledge production is largely a combination of the original knowledge, and the development of artificial intelligence not only helps people discover new knowledge, but also helps People effectively combine existing knowledge. Several authors implanted the process of knowledge combination in the model of Jones (1995) and used this new model to analyze the influence of artificial intelligence technology. It was found that the introduction of artificial intelligence technology will enable the economy to achieve significant growth by promoting a combination of knowledge. 2. Arguments on Artificial Intelligence and Economic Growth There is much controversy about how artificial intelligence will affect economic growth. In this section, we will discuss two important issues. The first argument is whether artificial intelligence technology can really bring about economic growth. The second argument is whether artificial intelligence technology can really trigger the arrival of "Economic Singularity." (1) Can artificial intelligence bring about economic growth? The discussion on this issue is actually a continuation of the discussion on Solow Paradox. "Solo's Paradox", also known as Productivity Paradox, was proposed by Robert Solow when he discussed the influence of computers. At the time, he lamented that technological change can be seen everywhere, but statistical data did not show the impact of technology on growth. Since then, many studies have supported this observation by Solow and believe that the emergence of new technologies including computers and the Internet has not had a substantial impact on economic growth. Representatives of such views are Tyler Cowen and Robert Gordon. Cowen pointed out in a bestseller that the computers and internet technologies that are considered to be very important have not made breakthroughs in productivity as in the previous technological revolution, and have seen from the current technological development, all "low hanging fruits". All have been taken away, so the economy will be stuck in a long period of "great stagnation." Gordon's analysis of the long-term trends in the economic growth of the United States reveals that recent technological advances have in fact only brought about a very low productivity improvement. The rise of artificial intelligence technology also encountered the challenge of "Solo's paradox." Although intuitively speaking, artificial intelligence has had an important impact on all aspects of production and life, but so far, empirical evidence is equally difficult to confirm this effect. In a famous debate, Gordon and other scholars questioned the role of artificial intelligence, saying that people's expectation is obviously too high. Regarding the questioning of "technical skeptics", the "techno-optimists" represented by Brynjolfsson clearly expressed their opposition. According to Brynjolfsson and his collaborators, modern technologies such as computers and the Internet have undoubtedly played a key role in increasing productivity and promoting economic growth. The impact of new technologies such as artificial intelligence may be even greater. As to why the contribution of technologies such as artificial intelligence cannot be seen in statistics, Brynjolfsson et al (2017) gave a detailed discussion. In their view, there are four possible reasons that can be used to explain the deviation between people's subjective perception of technological progress and statistical data. The first explanation is "false hopes", that is, people do overestimate the effect of technological progress. In fact, technology does not bring about the productivity improvement that people expect. The second explanation is "mismeasurement", which means that statistical data does not really reflect the output of technological progress, and thus underestimates its growth effect. The third explanation is “concentrated distribution and rent dissipationâ€, that is, although new technologies such as artificial intelligence can actually increase productivity, only a few star companies enjoy the resulting benefits. the benefits of. This not only exacerbates the inequality of income distribution, but also allows a small number of companies to obtain higher market power, which in turn leads to a decline in productivity. The fourth explanation is the implementation lag. The play of new technologies requires the supporting technology, infrastructure, and organizational structure adjustment as the basis. In view of the current situation, these supporting tasks are relatively lagged, and as a result, the power of artificial intelligence may not be fully utilized. Several authors examined each of the four possible explanations one by one and found that the last explanation was the most convincing. Therefore, they believe that the role of artificial intelligence can not be ignored, but the lagging supporting work at the current stage has limited its role. With the completion of related supporting work, the power of the "Artificial Intelligence Revolution" will gradually be released. (2) Will artificial intelligence bring "economic singularities"? Singularity was originally a mathematical term referring to a point that was not well-defined (eg, tends to infinity) or that had strange properties. The futurist Kurzweil borrowed the term in his own book to refer to artificial intelligence that transcends humanity and triggers a critical moment in the dramatic changes in human society. The so-called “economic singularity†refers to a key point in time. When this point is crossed, the economy will continue to grow and the growth rate will continue to accelerate. In history, many economic masters have had problems with “economic singularities,†and Keynes, the founder of macroeconomics, and Herbert Simon, the Nobel Prize winner, are among them. Although none of these embarrassment has become a reality until now, with the development of artificial intelligence technology, the discussion about “economic singularities†has started to soar. Some “technical optimist†scholars believe that “artificial singularities†will soon come as artificial intelligence can significantly increase productivity and can accomplish many tasks that humans cannot accomplish. This "technical optimist" view has caused a lot of controversy. Nordhaus (2015) questioned this in terms of experience. Nordhaus pointed out: First of all, as the new technology matures, their prices have dropped sharply, so their contribution to the economy has also rapidly declined. This means that relatively backward industries, rather than new industries, will become the key to economic growth. Second, although people have given many hopes for new technologies such as the Internet and artificial intelligence, they have not actually brought about a substantial increase in productivity. Again, at least from the reality of the United States, the current prices of investment products did not experience a rapid decline, and investment did not show rapid growth. Based on the above analysis, Nordhaus thinks that "economic singularity" may still be just a distant dream. Aghion et al (2017) theoretically analyzed “economic singularitiesâ€. They believe that whether or not the "economic singularity" can come depends on whether the bottleneck of knowledge growth can be broken. Although the endogenous growth model has demonstrated that knowledge can be produced as a product, this process requires the participation of people. As economic growth progresses, population growth slows down, and manpower that can be used as a factor of production to invest in knowledge production processes will also be reduced. Unless artificial intelligence can replace humans for creative work and knowledge production, this important bottleneck can hardly be broken. At least for now, artificial intelligence has not yet reached this level. (II) Artificial Intelligence and Employment Technological advancement will lead to "technical unemployment" while promoting productivity growth. As a revolutionary technology, artificial intelligence is no exception. Compared with previous technological revolutions in the past, the “artificial intelligence revolution†will have a broader impact on employment, and the intensity will be greater and last longer. At present, the possible impact of artificial intelligence on employment has become an important policy topic, and many literatures have discussed this. It should be pointed out that since artificial intelligence is usually treated as an enhanced version of automation when discussing the impact of artificial intelligence on employment and income distribution, in the following two sections, we introduce literature on the impact of artificial intelligence. The literature on automation and robotic influences will also be introduced. 1. Theoretical analysis of the effects of artificial intelligence and automated employment The ALM model proposed by Autor et al. (2003) is a benchmark model for studying the effects of artificial intelligence and automated employment. In the ALM model, production requires two kinds of tasks--a stylized task and an unstructured task. The stylized task requires only low-skilled labor, while the non-stylized task requires highly-skilled labor.åœ¨å‡ ä½ä½œè€…看æ¥ï¼Œè‡ªåŠ¨åŒ–åªèƒ½ç”¨æ¥å®Œæˆç¨‹å¼åŒ–任务,而ä¸èƒ½ç”¨æ¥å®Œæˆéžç¨‹å¼åŒ–ä»»åŠ¡ï¼Œå› æ¤å®ƒå¯¹ä½ŽæŠ€èƒ½åŠ³åŠ¨å½¢æˆäº†æ›¿ä»£ï¼Œè€Œå¯¹é«˜æŠ€èƒ½åŠ³åŠ¨åˆ™å½¢æˆäº†äº’补。在这ç§å‡è®¾ä¸‹ï¼Œè‡ªåŠ¨åŒ–的冲击将是åå‘æ€§çš„ï¼Œå®ƒå¯¹ä½ŽæŠ€èƒ½åŠ³åŠ¨è€…é€ æˆæŸå®³ï¼Œä½†å´ä¼šç»™é«˜æŠ€èƒ½åŠ³åŠ¨è€…带æ¥å¥½å¤„。 Frey and Osborne(2013)对ALM模型进行了拓展。在新的模型ä¸ï¼Œè€Œéžç¨‹å¼åŒ–任务则既需è¦ç¨‹å¼åŒ–劳动需è¦é«˜æŠ€èƒ½åŠ³åŠ¨å’Œä½ŽæŠ€èƒ½åŠ³åŠ¨çš„å…±åŒæŠ•å…¥ã€‚在这ç§è®¾å®šä¸‹ï¼Œè‡ªåŠ¨åŒ–对于高技能劳动者的作用将是ä¸ç¡®å®šçš„,在一定æ¡ä»¶ä¸‹å®ƒä»¬ä¹Ÿä¼šå—到自动化的æŸå®³ã€‚ Benzell et al(2015)在一个跨期è¿ä»£ï¼ˆOLG)模型ä¸è®¨è®ºäº†æœºå™¨äººå¯¹åŠ³åŠ¨åŠ›è¿›è¡Œæ›¿ä»£çš„问题。他们指出,在一定æ¡ä»¶ä¸‹ï¼Œæœºå™¨äººå¯ä»¥å®Œå…¨æ›¿ä»£ä½ŽæŠ€èƒ½å·¥ä½œï¼Œå¹¶æ›¿ä»£ä¸€éƒ¨åˆ†é«˜æŠ€èƒ½å·¥ä½œï¼Œè¿™ä¼šå¯¼è‡´å¯¹åŠ³åŠ¨åŠ›éœ€æ±‚çš„å‡å°‘和工资的下é™ã€‚虽然在采用机器人åŽï¼Œç”±ç”Ÿäº§çŽ‡æå‡ä¼šå¸¦æ¥çš„ä»·æ ¼ä¸‹é™å¯ä»¥åœ¨ä¸€å®šç¨‹åº¦ä¸Šæ”¹å–„劳动者ç¦åˆ©ï¼Œä¸è¿‡ä»Žæ€»ä½“上讲它并ä¸èƒ½å®Œå…¨å¼¥è¡¥å°±ä¸šæ›¿ä»£å¯¹åŠ³åŠ¨åŠ›é€ æˆçš„æŸå®³ã€‚å› æ¤ï¼Œå‡ ä½ä½œè€…认为机器人的使用å¯èƒ½ä¼šå¸¦æ¥æ‰€è°“的“贫困化增长â€ï¼ˆImmiserizing Growth)——虽然ç»æµŽå¢žé•¿äº†ï¼Œä½†ç¤¾ä¼šç¦åˆ©å´ä¸‹é™äº†ã€‚为了防æ¢è¿™ç§çŽ°è±¡çš„å‘ç”Ÿï¼Œå‡ ä½ä½œè€…建议è¦æŽ¨å‡ºé’ˆå¯¹æ€§çš„培è®è®¡åˆ’,并对特定世代的人群进行补贴。 Acemoglu and Restrepoæž„é€ äº†ä¸€ä¸ªåŒ…æ‹¬å°±ä¸šåˆ›é€ çš„æ¨¡åž‹ã€‚åœ¨æ¨¡åž‹ä¸ï¼Œè‡ªåŠ¨åŒ–消çæŸäº›å°±ä¸šå²—ä½çš„åŒæ—¶ï¼Œä¹Ÿä¼šåˆ›é€ 出劳动更具有比较优势的新就业岗ä½ï¼Œå› æ¤å…¶å¯¹å°±ä¸šçš„净效应è¦çœ‹ä¸¤ç§æ•ˆåº”的相对程度。他们å‘现,在长期å‡è¡¡çš„æ¡ä»¶ä¸‹ï¼Œç»“æžœå–决于资本和劳动的使用æˆæœ¬ã€‚如果资本的使用æˆæœ¬ç›¸å¯¹äºŽå·¥èµ„足够地低,那么所有èŒä¸šéƒ½å°†è¢«è‡ªåŠ¨åŒ–ï¼›å之,自动化就会有一定的界é™ã€‚æ¤å¤–ï¼Œå‡ ä½ä½œè€…还指出,如果劳动本身是异质性的,那么自动化的进行还将导致劳动者内部收入差异的产生。 2ã€å…³äºŽäººå·¥æ™ºèƒ½å’Œè‡ªåŠ¨åŒ–就业影å“的实è¯åˆ†æž Autor et al (2003)对1960-1998年的美国劳动力市场进行了分æžã€‚结果å‘现在1970年之åŽï¼Œâ€œè®¡ç®—化â€ï¼ˆComputerization)导致了“æžåŒ–效应â€â€”—对程å¼åŒ–工作的需求大幅下é™ï¼Œä½†åŒæ—¶å¯¼è‡´äº†å¯¹éžç¨‹å¼åŒ–å·¥ä½œéœ€æ±‚çš„å¢žåŠ ã€‚å°¤å…¶æ˜¯åœ¨1980年之åŽï¼Œè¿™ç§è¶‹åŠ¿æ›´åŠ 明显。Goos and Manning(2007)利用英国数æ®å¯¹ALM模型的结论进行了检验,结果å‘现技术进æ¥åœ¨è‹±å›½ä¹Ÿå¯¼è‡´äº†â€œæžåŒ–效应â€çš„出现。éšåŽï¼ŒAutor and Dorn(2013)ã€Goos et al(2014)ç‰æ–‡çŒ®åˆ†åˆ«å¯¹ç¾Žå›½å’Œæ¬§æ´²çš„æ•°æ®è¿›è¡Œäº†åˆ†æžï¼Œä¹ŸåŒæ ·å‘现了“æžåŒ–效应â€çš„å˜åœ¨â€”—在技术进æ¥çš„å†²å‡»ä¸‹ï¼Œå¤§æ‰¹åˆ¶é€ ä¸šçš„å°±ä¸šæœºä¼šè¢«æœåŠ¡ä¸šæ‰€æŠ¢å 。 Graetz and Michaels(2015)分æžäº†1993-2007å¹´é—´17个国家的机器人使用åŠç»æµŽè¿è¡ŒçŠ¶å†µã€‚å‘现平å‡è€Œè¨€æœºå™¨äººçš„使用让这些国家的GDP增速上涨了0.37个百分点。åŒæ—¶ï¼Œæœºå™¨äººçš„ä½¿ç”¨è¿˜è®©ç”Ÿäº§çŽ‡èŽ·å¾—äº†å¤§å¹…å¢žåŠ ï¼Œå¹¶å‡å°‘了ä¸ã€ä½Žç«¯æŠ€èƒ½å·¥äººçš„劳动时间和强度。Acemoglu and Restrepo(2017)利用1990年到2007年间美国劳动力市场的数æ®è¿›è¡Œäº†ç ”究。结果å‘现,机器人和工人的比例æ¯å¢žåŠ åƒåˆ†ä¹‹ä¸€ï¼Œå°±ä¼šå‡å°‘0.18%-0.34%的就业岗ä½ï¼Œå¹¶è®©å·¥èµ„下é™0.25%-0.5%。 3ã€å…³äºŽäººå·¥æ™ºèƒ½å’Œè‡ªåŠ¨åŒ–就业影å“çš„é¢„æµ‹å’Œè¶‹åŠ¿åˆ†æž é™¤äº†å®žè¯ç ”究外,也有ä¸å°‘å¦è€…采用ä¸åŒçš„方法对人工智能对就业的影å“进行了预测,其结果相差很大。Frey and Osborne(2013)曾对美国的702个就业岗ä½è¢«äººå·¥æ™ºèƒ½å’Œè‡ªåŠ¨åŒ–替代的概率进行了分æžï¼Œç»“果表明47%çš„å²—ä½é¢ä¸´ç€è¢«äººå·¥æ™ºèƒ½æ›¿ä»£çš„风险。Chui,Manyika,and Miremadi, (2015)则预测,美国45%的工作活动å¯ä»¥ä¾é 现有技术水平的机器æ¥å®Œæˆï¼›è€Œå¦‚果人工智能系统的表现å¯ä»¥è¾¾åˆ°äººç±»ä¸ç‰æ°´å¹³ï¼Œè¯¥æ•°å—将增至58%。相比之下,Arntz, M., Gregory,T., and Zierahn(2016)的预测则è¦ä¹è§‚得多,他们认为OECD国家的工作ä¸ï¼Œåªæœ‰çº¦9%的工作会被å–代。在国内,陈永伟和许多(2018)用Frey and Osborne(2013)的方法对ä¸å›½çš„就业岗ä½è¢«äººå·¥æ™ºèƒ½å–代的概率进行了估计,结果显示在未æ¥20å¹´ä¸ï¼Œæ€»å°±ä¸šäººçš„76.76%会éå—到人工智能的冲击,如果åªè€ƒè™‘éžå†œä¸šäººå£ï¼Œè¿™ä¸€æ¯”例是65.58%。 除了基于计é‡æ–¹æ³•çš„预测外,也有一些ç»æµŽå²å¦è€…æ ¹æ®åŽ†å²ç»éªŒå¯¹äººå·¥æ™ºèƒ½çš„就业影å“进行了分æžã€‚在一次麻çœç†å·¥å¦é™¢ç»„ç»‡çš„ç ”è®¨ä¼šä¸Šï¼ŒGordon指出从第一次工业é©å‘½ä»¥æ¥çš„è¿™250年间,还没有哪个å‘明引起了大规模的失业。尽管工作岗ä½æŒç»åœ°åœ¨æ¶ˆå¤±ï¼Œå´æœ‰æ›´å¤šçš„就业机会涌现了出æ¥ã€‚在他看æ¥ï¼ŒåŒæ ·çš„机制将会ä¿è¯â€œäººå·¥æ™ºèƒ½é©å‘½â€å¹¶ä¸ä¼šé€ æˆå‰§çƒˆçš„冲击。而Mokyr则认为,éšç€ç»æµŽçš„å‘展,æœåŠ¡æ€§è¡Œä¸šçš„比例将会上å‡ï¼Œè¿™äº›è¡Œä¸šç›¸å¯¹æ¥è¯´è¾ƒéš¾è¢«äººå·¥æ™ºèƒ½æ‰€æ›¿ä»£ã€‚å³ä½¿äººå·¥æ™ºèƒ½æ›¿ä»£äº†å…¶ä¸çš„一部分岗ä½ï¼Œä½†è€é¾„化ç‰é—®é¢˜ä¼šå¸¦æ¥å·¨å¤§çš„劳动力需求,由æ¤æ供的就业岗ä½å°†è¶³ä»¥æŠµæ¶ˆäººå·¥æ™ºèƒ½å¸¦æ¥çš„å½±å“。 æ¤å¤–,还有一些å¦è€…认为在分æžäººå·¥æ™ºèƒ½çš„就业影å“时,应当综åˆè€ƒè™‘其他å„ç§å› ç´ ã€‚ä¾‹å¦‚Goolsbee(2018ï¼‰è®¤ä¸ºçŽ°æœ‰çš„ç ”ç©¶å¤§å¤šæ˜¯ä»ŽæŠ€æœ¯å¯è¡Œæ€§è§’度去æ€è€ƒäººå·¥æ™ºèƒ½çš„就业影å“,而没有分æžä»·æ ¼å› ç´ å’Œè°ƒæ•´æˆæœ¬ï¼Œä¹Ÿæ²¡æœ‰è€ƒè™‘冲击的æŒç»æ—¶é—´ã€‚æ˜¾ç„¶ï¼Œå¦‚æžœå¿½ç•¥äº†è¿™äº›å› ç´ ï¼Œåªæ˜¯æŠ½è±¡åœ°è¯´äººå·¥æ™ºèƒ½ä¼šæ›¿ä»£å¤šå°‘劳动力,其政ç–æ„义将大打折扣。 4ã€å¯¹äºŽäººå·¥æ™ºèƒ½å°±ä¸šå½±å“的政ç–探讨 尽管ä¸åŒå¦è€…关于“人工智能é©å‘½â€å½±å“的估计å˜åœ¨å¾ˆå¤§å·®å¼‚,但大部分å¦è€…都认为,åŒåŽ†å²ä¸Šçš„å„次技术é©å‘½ä¸€æ ·ï¼Œâ€œäººå·¥æ™ºèƒ½â€åœ¨é•¿æœŸå°†ä¼šåˆ›é€ 出足够多的新岗ä½ä»¥ä»£æ›¿è¢«å…¶æ‘§æ¯çš„å²—ä½ï¼Œå› æ¤é—®é¢˜çš„关键就是通过政ç–平滑好çŸæœŸçš„冲击,让就业结构完æˆé¡ºåˆ©è½¬æ¢ã€‚ 应对çŸæœŸå°±ä¸šå†²å‡»çš„最é‡è¦æ”¿ç–æ˜¯åŠ å¼ºæ•™è‚²ã€‚å¾ˆå¤šç ”ç©¶æŒ‡å‡ºï¼Œâ€œäººå·¥æ™ºèƒ½é©å‘½â€å¯¹å°±ä¸šçš„最大影å“并ä¸æ˜¯è®©å°±ä¸šå²—ä½ç»å¯¹å‡å°‘了,而是从旧岗ä½è¢«æ·˜æ±°çš„那部分劳动者ä¸é€‚应新岗ä½ã€‚å› æ¤ï¼Œä¸ºäº†è®©åŠ³åŠ¨è€…们适应新岗ä½ï¼Œæ”¿åºœåº”当负责æ供教育和èŒä¸šæŒ‡å¯¼ã€‚由于“人工智能é©å‘½â€çš„冲击是æŒç»æ€§çš„ï¼Œå› æ¤ç›¸å…³çš„教育也应当有æŒç»æ€§ã€‚为了解决失业人员的培è®æ”¯å‡ºï¼Œå¯ä»¥æŽ¢ç´¢â€œå·¥ä½œæŠµæŠ¼è´·æ¬¾â€ï¼Œè®©å¤±ä¸šäººå‘˜ä»¥æœªæ¥èŽ·å¾—的工作为抵押æ¥èŽ·å–贷款,用以进行相关培è®ã€‚ ï¼ˆä¸‰ï¼‰äººå·¥æ™ºèƒ½ä¸Žæ”¶å…¥åˆ†é… äººå·¥æ™ºèƒ½å¯èƒ½é€šè¿‡å¤šä¸ªæ¸ é“对收入分é…å‘生影å“。首先,从ç†è®ºä¸Šè®²ï¼Œäººå·¥æ™ºèƒ½æ˜¯ä¸€ç§åå‘性的技术(Directed Technical Change或Biased Technical Change),它的使用会对ä¸åŒç¾¤ä½“的边际产出产生ä¸åŒä½œç”¨ï¼Œè¿›è€Œå½±å“他们的收入状况。这ä¸æ•ˆåº”体现在两个层次上,第一个层次是在ä¸åŒè¦ç´ 之间,这主è¦ä¼šå½±å“ä¸åŒè¦ç´ 回报的分é…;第二个层次是在劳动者内部,这主è¦å½±å“ä¸åŒæŠ€èƒ½æ°´å¹³çš„劳动者的收入分é…ã€‚å…¶æ¬¡ï¼Œäººå·¥æ™ºèƒ½çš„ä½¿ç”¨è¿˜ä¼šå¯¹å¸‚åœºç»“æž„é€ æˆæ”¹å˜ï¼Œè®©ä¸€äº›ä¼ä¸šèŽ·å¾—更高的市场力é‡ï¼Œè¿›è€Œè®©ä¼ä¸šæ‹¥æœ‰è€…获得更多的剩余收入。当然,以上这些效应最终如何起作用,还和相关的政ç–有很大关系。 1ã€äººå·¥æ™ºèƒ½å¯¹äºŽè¦ç´ å›žæŠ¥çš„å½±å“ è¦ç´ å›žæŠ¥çš„å·®å¼‚æ˜¯é€ æˆæ”¶å…¥åˆ†é…差别的最主è¦åŽŸå› 之一。近年æ¥ï¼Œèµ„æœ¬å›žæŠ¥çŽ‡åœ¨å…¨ä¸–ç•ŒèŒƒå›´å†…éƒ½å‘ˆçŽ°å‡ºäº†å¢žåŠ çš„è¶‹åŠ¿ï¼Œæ›´å¤šçš„æ”¶å…¥å’Œè´¢å¯Œå‘少数资本所有者èšé›†ï¼Œè¿™å¯¼è‡´äº†ä¸å¹³ç‰çš„åŠ å‰§ã€‚è€Œäººå·¥æ™ºèƒ½æŠ€æœ¯çš„åº”ç”¨ï¼Œåˆ™å¯èƒ½å¼ºåŒ–è¿™ç§è¦ç´ 收益的ä¸å¹³ç‰ã€‚ 人工智能是一ç§â€œæŠ€æœ¯åå‘性â€çš„技术。一方é¢ï¼Œå®ƒçš„æ™®åŠå°†ä¼šå‡å°‘市场上对劳动力的需求,进而é™ä½ŽåŠ³åŠ¨åŠ›çš„回报率;而与æ¤åŒæ—¶ï¼Œä½œä¸ºä¸€ç§èµ„本密集型技术,它å¯ä»¥è®©èµ„本回报率大为æå‡ã€‚在这两方é¢å› ç´ çš„ä½œç”¨ä¸‹ï¼Œèµ„æœ¬å’ŒåŠ³åŠ¨è¿™ä¸¤ç§è¦ç´ 的回报率差别会继ç»æ‰©å¤§ï¼Œè¿™ä¼šå¼•å‘收入ä¸å¹³ç‰çš„进一æ¥æ”€å‡ã€‚ 2ã€äººå·¥æ™ºèƒ½å¯¹ä¸åŒåŠ³åŠ¨è€…çš„å½±å“ æŠ€æœ¯çš„åå‘性ä¸ä»…体现在ä¸åŒç”Ÿäº§è¦ç´ 之间,还体现在劳动者群体内部,ä¸åŒæŠ€èƒ½åŠ³åŠ¨è€…在é¢ä¸´æŠ€æœ¯è¿›æ¥åŽï¼Œå…¶æ”¶å…¥å˜åŒ–会有很大差异。从性质上看,人工智能是技术åå‘性的,它对于ä¸åŒå°±ä¸šå²—ä½çš„冲击并ä¸ç›¸åŒã€‚人工智能的一个é‡è¦ä½œç”¨æ˜¯è‡ªåŠ¨åŒ–,而目å‰å·²æœ‰å¾ˆå¤šç ”究è¯æ˜Žäº†è‡ªåŠ¨åŒ–对ä¸åŒæŠ€èƒ½åŠ³åŠ¨è€…带æ¥çš„ä¸åŒå½±å“。 在现阶段,éå—自动化冲击较为严é‡ä¸»è¦æ˜¯é‚£äº›ä»¥ç¨‹å¼åŒ–任务为主,对技能è¦æ±‚较低的èŒä¸šã€‚自动化的普åŠä¸ä»…压低了从事这些èŒä¸šçš„åŠ³åŠ¨è€…çš„æ”¶å…¥ï¼Œè¿˜é€ æˆäº†ç›¸å½“æ•°é‡çš„相关人员失业。而如æ¤åŒæ—¶ï¼Œè‡ªåŠ¨åŒ–对那些éžç¨‹å¼åŒ–ã€å¯¹æŠ€èƒ½è¦æ±‚较高的èŒä¸šï¼Œåˆ™ä¸»è¦èµ·åˆ°äº†å¼ºåŒ–å’Œè¾…åŠ©ä½œç”¨ï¼Œå› æ¤é¢å¯¹â€œäººå·¥æ™ºèƒ½é©å‘½â€çš„冲击,从事这些èŒä¸šçš„劳动者的收入ä¸ä»…没有下é™ï¼Œå而出现了上å‡ã€‚尽管关于人工智能的技能åå‘æ€§çš„ç ”ç©¶è¿˜è¾ƒå°‘ï¼Œä½†ä»Žé€»è¾‘ä¸Šè®²ï¼Œä½œä¸ºä¸€ç§å®žçŽ°é«˜çº§è‡ªåŠ¨åŒ–的技术,它也将会产生类似的效应。 需è¦æŒ‡å‡ºçš„是,éšç€äººå·¥æ™ºèƒ½æŠ€æœ¯çš„å‘展,自动化的范围已ç»ä¸å†åƒè¿‡åŽ»é‚£æ ·å±€é™äºŽç¨‹å¼åŒ–较强,对技能è¦æ±‚较低的èŒä¸šï¼Œå¾ˆå¤šç¨‹å¼åŒ–较低ã€å¯¹æŠ€èƒ½è¦æ±‚很高的èŒä¸šï¼Œå¦‚医生ã€å¾‹å¸ˆä¹Ÿé¢ä¸´ç€è‡ªåŠ¨åŒ–的冲击。在这ç§èƒŒæ™¯ä¸‹ï¼Œå½“分æžè‡ªåŠ¨åŒ–çš„å½±å“时就需è¦å¯¹è‡ªåŠ¨åŒ–的类别进行分æžã€‚如果自动化是对低技能劳动进行替代,那么它将会扩大工资的ä¸å¹³ç‰ï¼›è€Œå¦‚果自动化是对高技能劳动进行替代,那么它或许将有助于缩å°æ”¶å…¥çš„ä¸å¹³ç‰ã€‚ 3ã€äººå·¥æ™ºèƒ½å¯¹åˆ©æ¶¦åˆ†é…çš„å½±å“ é™¤äº†æ”¹å˜è¦ç´ 的边际收益外,人工智能还会å¯èƒ½é€šè¿‡å¦ä¸€æ¡é—´æŽ¥æ¸ é“——改å˜å¸‚场力é‡æ¥å¯¹æ”¶å…¥åˆ†é…产生影å“。 ç»æµŽå¦çš„基本ç†è®ºå‘Šè¯‰æˆ‘们,当市场结构ä¸æ˜¯å®Œå…¨ç«žäº‰æ—¶ï¼Œå¸‚场ä¸çš„ä¼ä¸šå°±å¯èƒ½èŽ·å¾—ç»æµŽåˆ©æ¶¦ï¼Œè€Œç»æµŽåˆ©æ¶¦çš„高低则和ä¼ä¸šçš„市场力é‡å¯†åˆ‡ç›¸å…³ã€‚è¿‘å¹´æ¥ï¼Œä¸–ç•Œå„国的市场结构都呈现出了集ä¸çš„趋势,大é‡å æ®é«˜å¸‚场份é¢çš„“超级明星ä¼ä¸šâ€ï¼ˆSuperstar Firms)开始出现,并å‡å€Ÿå·¨å¤§çš„市场力é‡èŽ·å¾—å·¨é¢åˆ©æ¶¦ã€‚ ä¸å°‘å¦è€…认为,高技术的使用是导致“超级明星ä¼ä¸šâ€ä¸€ä¸ªé‡è¦åŽŸå› ,而人工智能作为一ç§é‡è¦çš„新技术显然会强化这一趋势。ä¸è¿‡ï¼Œå°±ç¬”者所知,目å‰è¿˜æ²¡æœ‰æ–‡çŒ®å¯¹äººå·¥æ™ºèƒ½å½±å“收入分é…çš„è¿™ä¸€æ¸ é“进行过专门的实è¯åˆ†æžï¼Œå› æ¤è¿™ç§çŒœæµ‹æš‚æ—¶åªå˜åœ¨äºŽç†è®ºå±‚é¢ã€‚ 4ã€æ”¿ç–对人工智能分é…æ•ˆåº”çš„å½±å“ æŠ€æœ¯å˜è¿çš„收入分é…效应必然å—到政ç–å› ç´ çš„å½±å“,åˆç†çš„政ç–措施å¯ä»¥è®©æŠ€æœ¯å˜è¿è¿‡ç¨‹æ›´æœ‰åŒ…容性,使所有人更好地共享技术å˜è¿çš„æˆæžœã€‚Korinek and Stiglitz(2017)曾对“人工智能é©å‘½â€ä¸çš„分é…政ç–进行过讨论。他们指出,尽管åƒäººå·¥æ™ºèƒ½è¿™æ ·çš„技术进æ¥å¯ä»¥è®©ç¤¾ä¼šæ€»è´¢å¯Œå¢žåŠ ,但由于现实世界ä¸çš„人们ä¸å¯èƒ½å®Œå…¨ä¿é™©ï¼Œä¹Ÿä¸å¯èƒ½è¿›è¡Œæ— æˆæœ¬çš„收入分é…ï¼Œå› æ¤å°±éš¾ä»¥è®©è¿™äº›æŠ€æœ¯è¿›æ¥å¸¦æ¥å¸•ç´¯æ‰˜æ”¹è¿›ï¼Œåœ¨ä¸€äº›äººå› 技术进æ¥å—益的åŒæ—¶ï¼Œå¦ä¸€äº›äººåˆ™ä¼šå—到æŸå®³ã€‚为了æ‰è½¬è¿™ç§æƒ…况,政ç–的介入是必è¦çš„。政ç–必须对技术进æ¥å¸¦æ¥çš„两ç§æ•ˆåº”——剩余的集ä¸å’Œç›¸å¯¹ä»·æ ¼çš„å˜åŒ–åšå‡ºå›žåº”,而为了达到目的,税收ã€çŸ¥è¯†äº§æƒæ”¿ç–ã€ååž„æ–政ç–ç‰æ”¿ç–都å¯ä»¥å‘挥一定作用。Kaplan(2015)对相关收入分é…政ç–进行了全é¢æŽ¢è®¨ã€‚他建议,考虑到人工智能对ä¸åŒäººç¾¤å¸¦æ¥çš„ä¸åŒå½±å“ï¼Œåº”è¯¥è€ƒè™‘å¯¹é‚£äº›å› è¿™é¡¹æŠ€æœ¯èŽ·ç›Šçš„äººå¾ç¨Žï¼Œç”¨æ¥è¡¥è´´å› æ¤è€Œå—æŸçš„人们。Cowen(2017)指出,良好的社会规范将有助于政ç–作用的å‘æŒ¥ï¼Œå› æ¤åœ¨è¿›è¡Œæ”¶å…¥åˆ†é…时,必须è¦æ³¨æ„相关的社会规范的培育。 (四)人工智能与产业组织 æ¯«æ— ç–‘é—®ï¼Œäººå·¥æ™ºèƒ½æŠ€æœ¯çš„å‘展将对产业组织和市场竞争产生æžä¸ºæ˜¾è‘—çš„å½±å“。它将通过影å“市场结构ã€ä¼ä¸šè¡Œä¸ºï¼Œè¿›è€Œå½±å“到ç»æµŽç»©æ•ˆï¼Œè€Œæ‰€æœ‰çš„è¿™äº›çŽ°è±¡éƒ½å°†å¯¹ä¼ ç»Ÿçš„è§„åˆ¶å’Œç«žäº‰æ”¿ç–æ出新的挑战。 1ã€äººå·¥æ™ºèƒ½å¯¹å¸‚åœºç»“æž„çš„å½±å“ äººå·¥æ™ºèƒ½å¯¹äºŽå¸‚åœºç»“æž„çš„å½±å“æ˜¯é€šè¿‡ä¸¤ä¸ªæ¸ é“进行的。 ç¬¬ä¸€ä¸ªæ¸ é“是技术的直接影å“。使用人工智能技术的ä¼ä¸šå¯ä»¥èŽ·å¾—生产率的跃å‡ï¼Œè¿™å°†ä½¿å®ƒä»¬æ›´å®¹æ˜“在激烈的市场竞争ä¸èƒœå‡ºã€‚åŒæ—¶ç”±äºŽäººå·¥æ™ºèƒ½æŠ€æœ¯éœ€è¦æŠ•å…¥è¾ƒé«˜çš„固定æˆæœ¬ï¼Œä½†è¾¹é™…æˆæœ¬å´è¾ƒä½Žï¼Œå› æ¤è¿™å°±èƒ½è®©ä½¿ç”¨äººå·¥æ™ºèƒ½çš„ä¼ä¸šå…·æœ‰äº†è¾ƒé«˜çš„è¿›å…¥é—¨æ§›ã€‚è¿™ä¸¤ä¸ªå› ç´ å åŠ åœ¨ä¸€èµ·ï¼Œå¯¼è‡´äº†å¸‚åœºå˜å¾—更为集ä¸ã€‚ ç¬¬äºŒä¸ªæ¸ é“是技术引å‘çš„ä¼ä¸šå½¢å¼å˜é©ã€‚ä¼ä¸šçš„组织形å¼æ˜¯éšæŠ€æœ¯çš„å˜åŒ–而å˜åŒ–的。在人工智能技术的冲击下,平å°ï¼ˆPlatform)æ£åœ¨æˆä¸ºå½“今ä¼ä¸šç»„织的一ç§é‡è¦å½¢å¼ã€‚由于平å°é€šå¸¸å…·æœ‰â€œè·¨è¾¹ç½‘络外部性â€ï¼Œå› 而会导致“鸡生蛋ã€è›‹ç”Ÿé¸¡â€ä¼¼çš„æ£å馈效应,这让平å°ä¼ä¸šå¯ä»¥è¿…速膨胀å 领市场,并形æˆä¸€å®¶ç‹¬å¤§çš„现象。 综åˆä»¥ä¸Šä¸¤ç§å› ç´ ï¼Œäººå·¥æ™ºèƒ½æŠ€æœ¯çš„è¿…é€Ÿå‘展推动了一批“超级巨星ä¼ä¸šâ€ä¼ä¸šçš„出现,并让市场迅速å˜å¾—高度集ä¸ã€‚ 需è¦æŒ‡å‡ºçš„是,人工智能对于市场结构的影å“ä¸ä»…åæ˜ åœ¨æ¨ªå‘关系上,还åæ˜ åœ¨çºµå‘关系上。Shapiro and Varian(2017)指出,由于机器å¦ä¹ 的特殊性,那些采用机器å¦ä¹ çš„ä¼ä¸šæ›´å€¾å‘于垂直è”åˆä»¥èŽ·å–更多数æ®å¹¶å‰Šå‡æœºå™¨å¦ä¹ çš„æˆæœ¬ã€‚æ ¹æ®è¿™ä¸€ç†è®ºæˆ‘们å¯ä»¥é¢„è§ï¼Œéšç€äººå·¥æ™ºèƒ½æŠ€æœ¯çš„å‘展,大型平å°ä¼ä¸šå¯¹ä¸‹æ¸¸çš„并è´è¶‹åŠ¿å°†ä¼šåŠ 强,而推动这ç§å¹¶è´æ•´åˆçš„åŠ¨å› å°†ä¸å†æ˜¯äº‰å¤ºç›´æŽ¥çš„利润或市场份é¢ï¼Œè€Œæ˜¯äº‰å¤ºæ•°æ®èµ„æºã€‚ 2ã€äººå·¥æ™ºèƒ½å¯¹ä¼ä¸šè¡Œä¸ºçš„å½±å“ äººå·¥æ™ºèƒ½æŠ€æœ¯çš„å‘展将会对ä¼ä¸šçš„ä¸å°‘行为å‘生影å“。很多以å‰éš¾ä»¥é‡‡ç”¨çš„ç–略将会å˜æˆçŽ°å®žã€‚ 一个例å是算法æ§è§†ï¼ˆAlgorithmic Discriminationï¼‰ã€‚åœ¨ä¼ ç»Ÿçš„ç»æµŽå¦ä¸ï¼Œç”±äºŽä¼ä¸šçš„ä¿¡æ¯è¶Šè‹ï¼Œâ€œä¸€çº§ä»·æ ¼æ§è§†â€åªåœ¨ç†è®ºä¸Šå‡ºçŽ°ã€‚而在人工智能时代,借用大数æ®å’Œæœºå™¨å¦ä¹ ,ä¼ä¸šå°†æœ‰å¯èƒ½å¯¹æ¯ä¸ªå®¢æˆ·ç²¾ç¡®ç”»åƒï¼Œå¹¶æœ‰é’ˆå¯¹æ€§åœ°è¿›è¡Œç´¢ä»·ï¼Œä»Žè€Œå®žçŽ°â€œä¸€çº§ä»·æ ¼æ§è§†â€ï¼ŒèŽ·å¾—全部的消费者剩余。å³ä½¿ä¼ä¸šä¸è¿›è¡Œâ€œä¸€çº§ä»·æ ¼æ§è§†â€ï¼Œäººå·¥æ™ºèƒ½æŠ€æœ¯ä¹Ÿèƒ½å¤Ÿå¸®åŠ©ä»–ä»¬æ›´å¥½åœ°è¿›è¡ŒäºŒçº§æˆ–ä¸‰çº§ä»·æ ¼æ§è§†ï¼Œä»Žè€Œæ›´å¥½åœ°æ”«å–消费者剩余。 å¦ä¸€ä¸ªä¾‹å是算法åˆè°‹ï¼ˆAlgorithmic Collusion)。åˆè°‹ä¸€ç›´æ˜¯äº§ä¸šç»„织ç†è®ºå’Œååž„æ–法关注的一个é‡è¦é—®é¢˜ã€‚市场上的ä¼ä¸šå¯ä»¥é€šè¿‡åˆè°‹æ¥ç“œåˆ†å¸‚场,从而æå‡ä¼ä¸šåˆ©æ¶¦çš„目的。产业组织ç†è®ºçš„知识告诉我们,ä¼ä¸šçš„è¿™ç§åˆè°‹ä¼šå¯¼è‡´äº§é‡å‡å°‘ã€ä»·æ ¼ä¸Šå‡ã€æ¶ˆè´¹è€…ç¦åˆ©å—æŸã€‚ä½†æ˜¯ï¼Œåœ¨ä¼ ç»Ÿçš„ç»æµŽæ¡ä»¶ä¸‹ï¼Œç”±äºŽå˜åœ¨ä¿¡æ¯äº¤æµå›°éš¾ä»¥åŠâ€œå›šå¾’困境â€ç‰é—®é¢˜ï¼Œåˆè°‹æ˜¯å¾ˆéš¾æŒä¹…的。尽管从ç†è®ºä¸Šè®²ï¼Œé‡å¤åšå¼ˆæœºåˆ¶å¯ä»¥å¸®åŠ©ä¼ä¸šåˆè°‹çš„实现,但事实上由于难以监ç£è¿çº¦ã€éš¾ä»¥æƒ©ç½šè¿çº¦ï¼Œä»¥åŠéš¾ä»¥è¯†åˆ«ç»æµŽä¿¡æ¯ç‰é—®é¢˜çš„å˜åœ¨ï¼Œè¿™ä¹Ÿå¾ˆéš¾çœŸæ£è¾¾æˆã€‚但éšç€äººå·¥æ™ºèƒ½æŠ€æœ¯çš„å‘展,过去很难达æˆçš„åˆè°‹å°†ä¼šå˜æˆå¯èƒ½ã€‚与过去ä¸åŒçš„是,ä¼ä¸šä¹‹é—´çš„åˆè°‹ä¸å†éœ€è¦ç›¸äº’猜测åˆè°‹ä¼™ä¼´çš„è¡ŒåŠ¨ï¼Œä¹Ÿæ— éœ€è¦é€šè¿‡æŸä¸ªä¿¡å·æ¥å调彼æ¤çš„行为。åªè¦é€šè¿‡æŸç§å®šä»·ç®—法,这些问题都å¯ä»¥å¾—到解决。在这ç§èƒŒæ™¯ä¸‹ï¼Œä¼ä¸šæ•°é‡çš„多少ã€äº§ä¸šæ€§è´¨ç‰å½±å“åˆè°‹éš¾åº¦çš„å› ç´ éƒ½å˜å¾—ä¸å†é‡è¦ï¼Œåœ¨ä»»ä½•æ¡ä»¶ä¸‹ä¼ä¸šéƒ½å¯ä»¥é¡ºåˆ©è¿›è¡Œåˆè°‹ã€‚ 除了算法æ§è§†ä»¥åŠç®—法åˆè°‹å¤–,人工智能技术的å‘展还会引å‘很多新的竞争问题。例如,平å°ä¼ä¸šå¯ä»¥å€ŸåŠ©æœç´¢å¼•æ“Žå½±å“人们的决ç–,或者通过算法æ¥å½±å“人们在平å°ä¸Šçš„匹é…结果。 (五)人工智能与贸易 人工智能对于贸易产生的影å“将是多方é¢çš„:其一,作为一ç§é‡è¦çš„技术进æ¥ï¼Œäººå·¥æ™ºèƒ½å°†å¯¹è¦ç´ 回报率产生é‡å¤§å½±å“,并改å˜ä¸åŒè¦ç´ 之间的相对回报状况,这会让å„国的动æ€æ¯”较优势状况å‘生明显的å˜åŒ–。其二,作为一个新兴的产业,人工智能的相关技术和人æ‰ä¹Ÿæˆä¸ºäº†è´¸æ˜“çš„é‡è¦å¯¹è±¡ï¼Œè€Œå„国的战略性贸易政ç–将会对该产业的å‘展产生关键作用。其三,在微观上,人工智能的使用也将影å“ä¼ä¸šçš„ç”Ÿäº§çŽ‡çŠ¶å†µï¼Œæ ¹æ®â€œæ–°æ–°è´¸æ˜“ç†è®ºâ€ï¼Œè¿™å°†ä¼šå½±å“ä¼ä¸šçš„出å£å†³ç–。 ä¸è¿‡ï¼Œç›®å‰åœ¨çŽ°æœ‰æ–‡çŒ®ä¸ç›´æŽ¥è®¨è®ºäººå·¥æ™ºèƒ½ä¸Žå›½é™…贸易的文献还相对较少,就笔者所知,Goldfarb and Trefler(2018)是目å‰å”¯ä¸€ä¸€ç¯‡å¯¹è¿™ä¸€é—®é¢˜è¿›è¡Œä¸“门讨论的论文。在这篇论文ä¸ï¼Œä¸¤ä½ä½œè€…首先指出了人工智能产业的两个é‡è¦ç‰¹ç‚¹ï¼šè§„模ç»æµŽä»¥åŠçŸ¥è¯†å¯†é›†ã€‚人工智能产业对于数æ®çš„ä¾èµ–éžå¸¸å¼ºï¼Œè§„模ç»æµŽçš„属性决定了它们在人å£åŸºæ•°æ›´ä¸ºåºžå¤§ã€å„类交易数æ®æ›´ä¸ºä¸°å¯Œçš„国家(如ä¸å›½ï¼‰æ›´å®¹æ˜“得到å‘展。而知识密集的特å¾åˆ™å†³å®šäº†çŸ¥è¯†çš„扩散ã€ä¼ æ’æ–¹å¼å°†å¯¹å„国人工智能的å‘展起到é‡è¦å½±å“。 在认识了人工智能产业的基本特å¾åŽï¼Œä¸¤ä½ä½œè€…讨论了战略性贸易ä¿æŠ¤æ”¿ç–在å‘展人工智能产业过程ä¸çš„有效性。在两ä½ä½œè€…看æ¥ï¼Œä¼ 统的战略性贸易ä¿æŠ¤æ–‡çŒ®æœ‰ä¸€ä¸ªé‡è¦çš„缺陷,å³åªæœ‰å½“å˜åœ¨ç€åˆ©æ¶¦æ—¶ï¼Œæˆ˜ç•¥æ€§è´¸æ˜“ä¿æŠ¤æ”¿ç–æ‰æ˜¯èµ·ä½œç”¨çš„。但是,一旦产业由于政府的ä¿æŠ¤è€Œäº§ç”Ÿäº†è¶…é¢åˆ©æ¶¦ï¼Œåªè¦è¿›å…¥é—¨æ§›è¶³å¤Ÿä½Žï¼Œæ›´å¤šçš„ä¼ä¸šå°±ä¼šè¿›å…¥è¿™ä¸ªäº§ä¸šï¼Œç›´è‡³åˆ©æ¶¦è¢«åŽ‹ç¼©åˆ°é›¶ã€‚而在这ç§æƒ…况下,战略性贸易ä¿æŠ¤æ”¿ç–就失效了。由于人工智能产业具有很强的网络外部性,所以在这个产业ä¸æœ‰ä¼ä¸šå…ˆè¡Œå‘展起æ¥ï¼Œå…¶è§„模就为其构ç‘起很高的进入门槛,这æ„味ç€å³ä½¿äº§ä¸šæœ‰å¾ˆé«˜çš„利润也ä¸ä¼šæœ‰æ–°ä¼ä¸šç»§ç»è¿›å…¥ã€‚在这ç§æ¡ä»¶ä¸‹ï¼Œæˆ˜ç•¥æ€§è´¸æ˜“ä¿æŠ¤æ”¿ç–就会å˜å¾—更有效了。 两ä½ä½œè€…é€šè¿‡å‡ ä¸ªæ¨¡åž‹å¯¹å‡ ç±»æ”¿ç–,如补贴政ç–ã€äººæ‰æ”¿ç–,以åŠé›†ç¾¤æ”¿ç–çš„å½±å“进行了讨论。他们指出,这些政ç–究竟是å¦èƒ½æˆåŠŸï¼Œä¸»è¦è¦çœ‹äººå·¥æ™ºèƒ½æ‰€ä¾èµ–的知识外部性究竟æ¥è‡ªäºŽæœ¬å›½èŒƒå›´è¿˜æ˜¯ä¸–界范围。如果人工智能ä¾èµ–的知识外部性主è¦æ¥è‡ªäºŽæœ¬å›½ï¼Œé‚£ä¹ˆæ”¿åºœå°±å¯ä»¥é€šè¿‡äº§ä¸šæ”¿ç–和战略性贸易ä¿æŠ¤æ”¿ç–对ä¼ä¸šè¿›è¡Œæœ‰æ•ˆæ‰¶æŒï¼Œä»Žè€Œè®©ä¼ä¸šåœ¨ä¸–界范围内更具有竞争力。但如果人工智能ä¾èµ–çš„çŸ¥è¯†å¤–éƒ¨æ€§æ˜¯å…¨ä¸–ç•ŒèŒƒå›´å†…çš„ï¼Œç”±äºŽçŸ¥è¯†çš„æ‰©æ•£ä¼šç›¸å½“å®¹æ˜“ï¼Œå› æ¤ä»¥ä¸Šæ”¿ç–的作用就ä¸ä¼šæ˜Žæ˜¾ã€‚ 在论文的最åŽï¼Œä¸¤ä½ä½œè€…ç€é‡å¯¹éšç§æ”¿ç–进行了讨论。从ç»éªŒä¸Šçœ‹ï¼Œæ›´å¼ºçš„éšç§ä¿æŠ¤ä¼šé™åˆ¶ä¼ä¸šå¯¹æ•°æ®çš„获å–,进而会阻ç¢ä»¥æ•°æ®ä¸ºå…³é”®èµ„æºçš„人工智能产业的å‘å±•ã€‚å› æ¤ï¼Œåœ¨å®žè·µä¸ï¼Œéšç§ä¿æŠ¤æ”¿ç–ç»å¸¸è¢«ä½œä¸ºéšæ€§çš„贸易ä¿æŠ¤æ”¿ç–æ¥å¯¹ä»˜å›½å¤–ä¼ä¸šã€‚但这两ä½ä½œè€…看æ¥ï¼Œè¿™ç±»æ”¿ç–也åŒæ—¶ä¼šæŸå®³æœ¬å›½ä¼ä¸šï¼Œå› æ¤æ˜¯ä¸å¯å–的。他们建议,出于支æŒæœ¬å›½ä¼ä¸šçš„目的,政府å¯ä»¥é‡‡ç”¨å…¶ä»–一些扶æŒæ”¿ç–,例如数æ®æœ¬åœ°åŒ–规则ã€å¯¹æ”¿åºœæ•°æ®è®¿é—®çš„é™åˆ¶ã€è¡Œä¸šç®¡åˆ¶ã€åˆ¶å®šæœ¬åœ°æ— 人驾驶法规,以åŠå¼ºåˆ¶è®¿é—®æºä»£ç ç‰ã€‚ (å…)人工智能与法律 人工智能的兴起带æ¥äº†å¾ˆå¤šæ–°çš„法律问题。 例如,人工智能在一定程度上å¯ä»¥æ›¿ä»£æˆ–辅助人进行决ç–,那么在这个过程ä¸äººå·¥æ™ºèƒ½æ˜¯å¦åº”该具有法律主体地ä½ï¼Ÿ 在应用ä¸ï¼Œäººå·¥æ™ºèƒ½éœ€è¦åˆ©ç”¨å…¶ä»–设备或软件è¿è¡Œè¿‡ç¨‹ä¸çš„æ•°æ®ï¼Œé‚£ä¹ˆè°æ˜¯è¿™äº›æ•°æ®çš„所有人,è°èƒ½å¤Ÿä½œå‡ºæœ‰æ•ˆçš„授æƒï¼Ÿ 在éé‡äººå·¥æ™ºèƒ½é€ æˆçš„事故或产å“责任问题时,应该如何区分人工æ“作还是人工智能本身的缺陷? å¯¹äºŽç®—æ³•é€ æˆçš„æ§è§†ã€åˆè°‹ç‰è¡Œä¸ºåº”当如何应对? ...... 这些问题都å分实际,但å´å……满了争议。é™äºŽç¯‡å¹…,笔者åªæƒ³å¯¹ä¸¤ä¸ªé—®é¢˜è¿›è¡Œä¸“门讨论,对于更多人工智能引å‘的法律问题的探讨,å¯ä»¥å‚考Pagallo(2013),Erzachi and Stucke(2016),Stucke and Grunes(2016)ç‰è‘—作。 1ã€äººå·¥æ™ºèƒ½å¸¦æ¥çš„éšç§æƒé—®é¢˜ 现阶段人工智能的应用是和数æ®å¯†ä¸å¯åˆ†çš„。例如商家在利用人工智能挖掘消费者å好时,就必须ä¾èµ–从消费者处æœé›†çš„æ•°æ®ï¼ˆåŒ…括身份信æ¯ã€äº¤æ˜“ä¹ æƒ¯æ•°æ®ç‰ï¼‰ã€‚对于消费者æ¥è®²ï¼Œè®©å•†å®¶æœé›†è¿™äº›æ•°æ®å°†æ˜¯æœ‰åˆ©æœ‰å¼Šçš„——一方é¢ï¼Œè¿™äº›æ•°æ®å¯ä»¥è®©å•†å®¶æ›´å……分地了解他们的å好,从而为他们更好地æœåŠ¡ï¼›å¦ä¸€æ–¹é¢ï¼Œæ¶ˆè´¹è€…的这些数æ®è¢«æœé›†åŽä¹Ÿä¼šå¸¦æ¥å¾ˆå¤šé—®é¢˜ï¼Œä¾‹å¦‚å¯èƒ½è¢«å•†å®¶è¿›è¡Œä»·æ ¼æ§è§†ï¼Œå—到商家的推销骚扰,在部分æžç«¯çš„情况下甚至å¯èƒ½å› æ¤è€Œå—到人身方é¢çš„å¨èƒã€‚ 在数æ®çš„æœé›†å’Œäº¤æ¢ä¸å¤ªé¢‘ç¹çš„情况下,消费者在éå—å› æ•°æ®å¼•å‘的麻烦时很容易追踪到责任æºå¤´ï¼Œå› æ¤ä»–们å¯ä»¥æœ‰æ•ˆåœ°å¯¹å‡ºè®©æ•°æ®è€Œå¸¦æ¥çš„风险进行æˆæœ¬æ”¶ç›Šåˆ†æžã€‚在ç†æ€§å†³ç–下,一些消费者会选择自愿出让自己的数æ®ã€‚ 但是,éšç€å¤§æ•°æ®å’Œäººå·¥æ™ºèƒ½æŠ€æœ¯çš„å‘展,这ç§æƒ…况å‘生了改å˜ï¼š (1)商家在æœé›†äº†æ•°æ®åŽå¯ä»¥æ›´æŒä¹…ä¿å˜ï¼Œå¯ä»¥åœ¨æœªæ¥è¿›è¡Œæ›´å¤šçš„ä½¿ç”¨ï¼Œå› æ¤æ¶ˆè´¹è€…出让数æ®è¿™ä¸€è¡Œä¸ºå¸¦æ¥çš„收益和éå—的累积风险之间将å˜å¾—å分ä¸å¯¹ç§°ï¼›ï¼ˆ2)由于现在商家æœé›†æ•°æ®çš„行为已ç»å˜å¾—å分频ç¹ï¼Œå½“消费者éå—了数æ®ç›¸å…³çš„问题åŽä¹Ÿå¾ˆéš¾åˆ¤æ–ç©¶ç«Ÿæ˜¯å“ªä¸ªå•†å®¶é€ æˆçš„é—®é¢˜ï¼Œå› æ¤äº‹å®žä¸Šå°±å¾ˆéš¾è¿›è¡Œè¿½è´£ï¼›ï¼ˆ3)商家在æœé›†æ¶ˆè´¹è€…æ•°æ®åŽï¼Œå¯èƒ½å¹¶æ²¡æœ‰æŒ‰ç…§å…¶äº‹å…ˆå‘æ¶ˆè´¹è€…æ‰¿è¯ºçš„é‚£æ ·åˆç†ä½¿ç”¨æ•°æ®ï¼Œè€Œæ¶ˆè´¹è€…å´å¾ˆéš¾æƒ©ç½šè¿™ç§è¡Œä¸ºã€‚ 在上述背景下,如何对数æ®ä½¿ç”¨è¿›è¡Œæœ‰æ•ˆæ²»ç†ï¼Œå¦‚何在ä¿æŠ¤æ¶ˆè´¹è€…åˆæ³•æƒç›Šçš„基础上有效利用数æ®å°±æˆä¸ºäº†ä¸€ä¸ªéœ€è¦å°¤å…¶å€¼å¾—关注的问题。目å‰ï¼Œå¯¹äºŽäººå·¥æ™ºèƒ½æ¡ä»¶ä¸‹å¦‚何ä¿æŠ¤æ¶ˆè´¹è€…éšç§çš„争议很多,有å¦è€…认为应当由政府进行更多监管,有å¦è€…认为应当由ä¼ä¸šè‡ªèº«è¿›è¡Œæ²»ç†ï¼Œæœ‰å¦è€…则认为应该由民间团体组织治ç†ã€‚总体æ¥è®²ï¼Œå‡ ç§æ€è·¯éƒ½å„æœ‰å…¶åˆ©å¼Šï¼Œå› æ¤è¿™ä¸€é—®é¢˜ç›®å‰ä»ç„¶æ˜¯ä¸€ä¸ªå¼€æ”¾æ€§é—®é¢˜ã€‚ 2ã€äººå·¥æ™ºèƒ½çš„产å“责任问题 人工智能åŠä½¿ç”¨äººå·¥æ™ºèƒ½æŠ€æœ¯çš„设备(如机器人)å¯ä»¥å¤§å¹…度æ高生产率,但åŒæ—¶ä¹Ÿä¼šæ›´å¤§çš„使用风险。在这ç§èƒŒæ™¯ä¸‹ï¼Œç•Œå®šäººå·¥æ™ºèƒ½çš„产å“责任,明确一旦å‘ç”Ÿäº†äº‹æ•…ï¼Œç©¶ç«Ÿäººå·¥æ™ºèƒ½åˆ¶é€ è€…éœ€ 3 Inch Compression Driver,Professional Horn Driver,3 Inch Titanium Tweeter,Neodymium Driver Guangzhou BMY Electronic Limited company , https://www.bmy-speakers.com





March 18, 2023